Home »
SQL
How to handle duplicate data in SQL?
In this article, we are going to learn about the duplicate data and the process to handle it in SQL.
Submitted by Manu Jemini, on March 05, 2018
The DISTINCT keyword uses to select records which are distinct. Using the DISTINCT keyword is simple and sweet as we only need to Use it after SELECT keyword and rest will be handled by the database.
This is can be the case with you that your table must contains the records with duplicate data. At some points we don’t want all the data but only few records which will have DISTINCT keys.
The Usage of DISTINCT keyword is as follow, as we only to do something like this:
SELECT DISTINCT name FROM A;
What this query will do is, it will fetch all the records from the table A but if the name is repeated multiple times it will only select it once and we will have a result with records which are not duplicate in nature.
Dummy data:
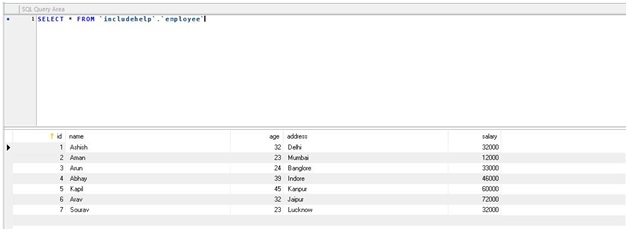
Syntax:
SELECT DISTINCT c1, c2, ..., cN
FROM t
WHERE [condition]
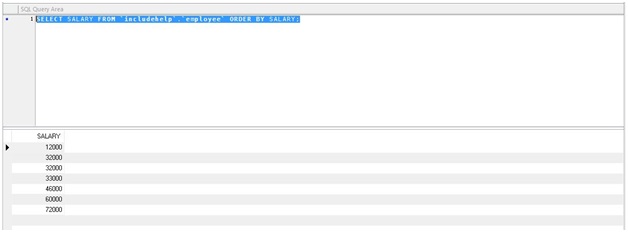
Example 1 - Without using DISTINCT keyword
SELECT SALARY FROM 'includehelp'.'employee'
ORDER BY SALARY;
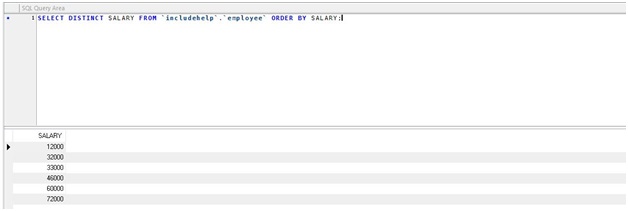
Example 2 - using DISTINCT keyword
SELECT DISTINCT SALARY FROM 'includehelp'.'employee'
ORDER BY SALARY;
Example 3 - using DISTINCT keyword
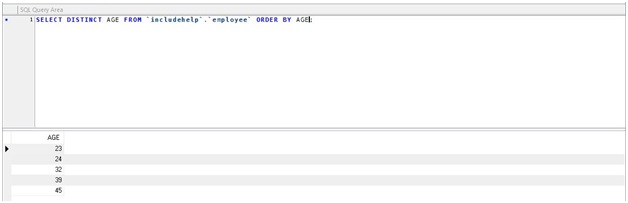
SELECT DISTINCT AGE FROM 'includehelp'.'employee'
ORDER BY AGE;