Home »
Python
Automating pdfs in Python
In this article, we will see how we can automate the pdf file with the help of PyPDF2 module in Python?
Submitted by Abhinav Gangrade, on July 12, 2020
Modules used:
In this script, we will use PyPDF2 module which will provide us various functions such as to extract the data and read the pdf file and split the file and write a new file.
Download PyPDF2:
- General Way: pip install PyPDF2
- Pycharm Users: Go to the python project interpreter and install it from there.
Various function provided by PyPDF2:
- PyPDF2.PdfFileReader(): This function will read our pdf and return us a data value that we will store in a variable (Let's take as Pdf_Data).
- Pdf_Data.isEncrypted: This Function will help us to check if the pdf file is Encrypted.
- Pdf_Data.decrypt("<password>"): This function will help us to decrypt the pdf file and inside this function, we have to put the password and our pdf file will get decrypted.
- Pdf_Data.numPages: This Function will return us the number of pages our pdf contain.
- Pdf_Data.getPage(0): This function will return us the data on the first page, here 0 seems to be the first page and 1 to be the second page, the things will go like indexing in python.
- Pdf_Writer=PyPDF2.PdfFileWriter(): This function will create a variable that will help us to create a new pdf file.
- Pdf_Writer.addPage(<The Page Data>): This function will add the pdf page to the newly created pdf file.
Note: The text Extraction can be done only with the pdf files which have text.
Python code to read the file and extract the text
# import the modules
import PyPDF2
# open the file and read the content
# open the file
Pdf_Open=open("/home/abhinav/Downloads/CS_Defination-converted.pdf","rb")
# read the file and store the content
Pdf_Data=PyPDF2.PdfFileReader(Pdf_Open)
# get the number of pages
print(Pdf_Data.numPages)
# Lets extract the data for the first page
# we will use getPage command to get the page
# using 0 for 1st page
First_page=Pdf_Data.getPage(0)
# printing the text
print(First_page.extractText())
Output:
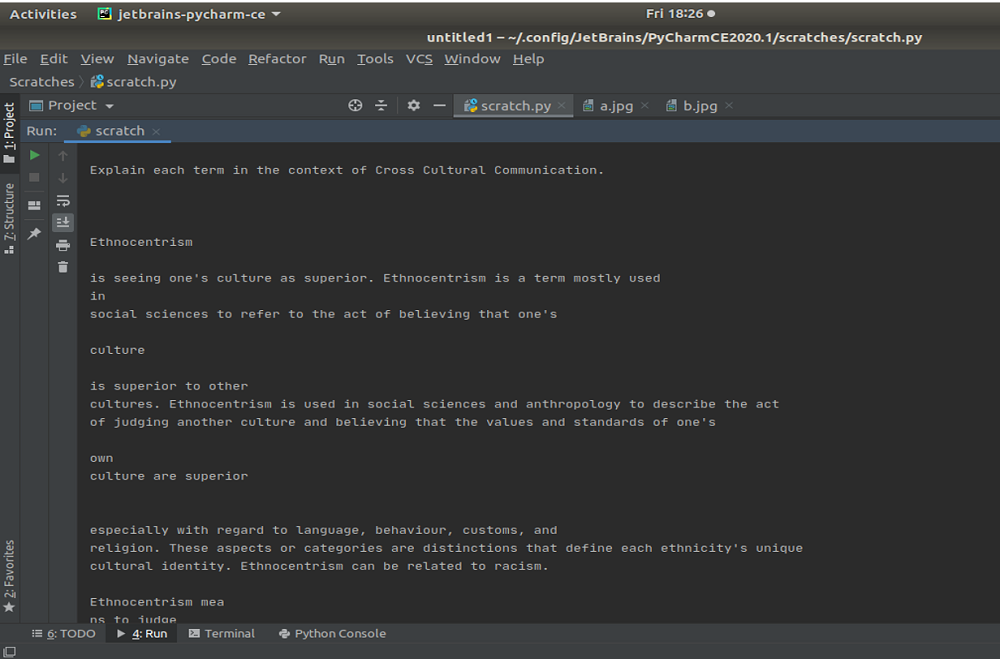
This is the extracted text from the pdf that we have given in input. In this way, we can extract the text from the pdf.
Now we will create a pdf file and we will add the starting and the last page of the above-used pdf in that file.
Let's see the code,
# import the modules
import PyPDF2
# open the file and read the content
# open the file
Pdf_Open=open("/home/abhinav/Downloads/Abhinav_Gangrade.pdf","rb")
# read the file and store the content
Pdf_Data=PyPDF2.PdfFileReader(Pdf_Open)
# get the number of pages
print(Pdf_Data.numPages)
# Create a pdf writer
pdf_writer=PyPDF2.PdfFileWriter()
# we will take the first page of the above pdf
first_page=Pdf_Data.getPage(0)
# we will take the last page of the above pdf
# as the last page will be Total number of pages-1
last_page=Pdf_Data.getPage((Pdf_Data.numPages)-1)
# adding page to the new pdf
pdf_writer.addPage(first_page)
pdf_writer.addPage(last_page)
# create a blank file
New_pdf=open("/home/abhinav/Downloads/Hello.pdf","wb")
# add the content to the blank file
pdf_writer.write(New_pdf)
# Now close the file
From the above code, we can create a new pdf with the help of an existing pdf, and after that, we have taken the first and last page of the existing pdf and combine them and wrote it in the new pdf. In that way, we can create a pdf with the help of existing pdfs.