Home »
Compiler Design
Introduction to Bottom Up Parser
In this article, we are going to learn about Introduction to Bottom Up Parser, its operations, classification.
Submitted by Anusha Sharma, on March 28, 2018
Bottom Up Parser
The process of constructing the parse tree in bottom up manner, i.e. starting with children and proceeds to the root are called Bottom Up Parser.
Handle
Substring of the given input string that matches R of any production is called Handle.
Note:
- BUP is also known as shift reduces parser.
- The BUP uses reverse of right most derivation.
- It has to detect the handle and reduce the handle.
- Detecting the handle is main overhead.
- BUP is constructed for unambiguous grammar, except for operating grammar.
- The BUP can be constructed for the grammar which is more complexity.
- This parsing mechanism is faster than Top down parsing.
- Performance of BUP is very high.
- Average time complexity is O(n^3).
BUP
BUP consists of mainly three components
- Input buffer: It consists of the input string to be parsed and input string ends with $.
- Parse stack: The stack consists of the grammar symbols. The grammar symbols are inserted or remove from the stack using shift and reduce operations.
-
Parse table: Parse table is constructed with number of terminals and number of non terminal and LR item. The parse table consists of two parts. First is action and second is goto.
- Action: Action part consists of shift and reduces operations implied for the terminals.
- Goto: It consists of shift operation which are applied on non terminals.
Operations
- Shift: Shift operations can be applied whenever handle does not occur from the top symbol of the stack.
- Reduce: Reduce operation can be used whenever handle occurs from the top symbol of stack.
- Accept: After processing the complete input string if stack contains only start of the grammar then the input string is accepted.
- Error: The processing of the input string if stack does not contain start symbol of the grammar then input string does not parse and it means parse tree is not constructed, so result is error.
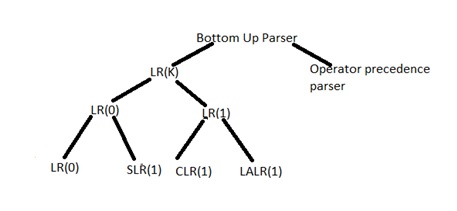
Classification of LR Parser
Based on construction of the table LR parser divided into four types
- LR(0)
- SLR(1)
- CLR(1)
- LALR(1)
Procedure for the construction of LR Parsing Table
- Obtain the augmented grammar for the given grammar.
- Create the canonical collection of LR items.
- Prepare the table based on LR items.
Augmented Grammar
The grammar which is obtained by adding one more production that derives the start symbol of the grammar is called augmented grammar.
Example:
If the given grammar is
S → AB
A → a
B → b
Then augmented grammar is
S` → S
S → AB
A → a
B → b
LR(0) Items in Compiler
A production '.' at any point in the right hand side is called LR(0) item.
Example:
A → abc
A → .abc
A → a.bc
A → ab.c
A → abc. (final item)
LR(0)
Conflicts In LR(0)
- SR conflict: If any state in DFA contains both shift and reduces option then it is called SR conflict.
- RR conflict: If the same state contains more than one final item then it is called RR conflict.
SLR(1) Parser
The procedure for constructing the parse table is similar to LR(0) parser but there is one restriction on reducing the entries. Whenever there is a final item then place the reduce entries under the follow symbols of left had side variable. If the SLR(1) parse table does not contain multiple entries that is free from conflicts is called SLR(1) grammar.
CLR(1) Parser
The grammar is LR(1) or CLR(1) if its parse table is free from multiple entries. For every grammar SLR(1) grammar is constructed then CLR(1) parser is also constructed we may or may not construct parse SLR(1). CLR(1) is more powerful than SLR(1). Number of entries in SLR(1) parse table are less than or equal to number of entries in CLR(1) parse table.
LALR(1) Parser
The DFA of CLR(1) parser contains some state with common production part differ by lookahead. Now combine the states with common productions part and different lookahead part into a single and construct a parse table if parse table is free from multiple entries then the grammar is LALR(1) parser.
Advertisement
Advertisement