Home »
Data Science
Naive Bayes Classifiers
In this article, we are going to learn about the Gaussian Naive Bayes classifier, its theorem and implementation using sci-kit-learn.
Submitted by Palkesh Jain, on March 11, 2021
Naive Bayes classifiers are a set of Bayes' Theorem-based classification algorithms. It is not a single algorithm but also a family of algorithms where a common concept is shared by all, i.e. each pair of features being classified is independent of each other.
For example -
Consider a fictitious dataset documenting the conditions of the weather for playing a golf game. Each tuple classifies the conditions as fit ("Yes") or unfit ("No") for playing golf, provided the weather conditions.
- The dataset is divided into two parts: the matrix of the function and the vector of the response.
- The feature matrix includes all of the dataset vectors (rows) in which each vector consists of dependent feature values. Features in the above dataset include 'Outlook',' Temperature',' Moisture', and 'Windy'.
- For each row of the feature matrix, the response vector contains the value of the class variable (prediction or output). The name of the class variable in the tuple above is 'Play golf'.
Assumption
The fundamental assumption of Naive Bayes is that each function makes one:
- Self-contained
- Equality
- The contribution to the performance.
With regard to our dataset, it is possible to understand this notion as.
- We assume that there are no dependent pairs of features. For instance, the 'Hot' temperature has nothing to do with the humidity, or the 'Rainy' outlook has no impact on the winds. Hence, it is assumed that the features are separate.
- Secondly, the same weight is given to every element (or importance). For instance, knowing only the temperature and humidity alone does not accurately predict the result. None of the attributes are trivial and are considered to contribute equally to the result.
Note:
In real-world circumstances, the assumptions made by Naive Bayes are not necessarily correct. In fact, the presumption of independence is never accurate, but it often works well in practice.
Now, it is important to know about the theorem of Bayes before moving to the formula for Naive Bayes.
Bayes' Theorem
Provided the likelihood of another occurrence that has already happened, Bayes' Theorem finds the probability of an event happening. The theorem of Bayes is stated as the following equation mathematically:
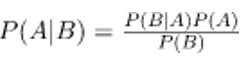
Where are events A and B and events P (B)? 0.
Basically, given the fact that event B is real, we are trying to find the likelihood of event A. Event B is often referred to as evidence.
P (A) is a 'priori' (the prior probability, i.e. Probability of event before evidence is seen). The proof is the attribute value of an unidentified case (here, it is event B).
P (A|B) is a posteriori B probability, i.e. likelihood of occurrence after proof is seen.
Now, with regard to our dataset, we may apply the theorem of Bayes as follows:
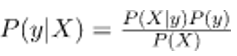
Where y is a variable of the class and X is a vector of a dependent function (of size n) where:
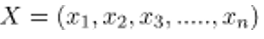
Just to be transparent, a function vector example and the corresponding class variable can be: (refer 1st row of dataset)
X = (Rainy, Hot, High, False)
y = No
In essence, P (y|X) suggests the possibility of "not playing golf" because the weather conditions are "rainy outlook", "hot temperature", "high humidity" and "no wind".
Naive assumption
Now, it's time to place the Bayes' theorem, which is independence between the characteristics, on a naive assumption. So now, we're breaking the proof into different pieces.
Now, if two cases, A and B, are autonomous, then,
P(A,B) = P(A)P(B)
Therefore, we have the result:
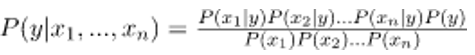
This may be represented as:
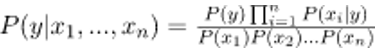
Now, because for a given input, the denominator remains constant, we can remove the term:
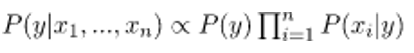
Now, we need to build a model of a classifier. For this, the probability of the input set given is found for all possible values of the y-class variable and the output is collected with maximum probability. Mathematically, this can be expressed as:
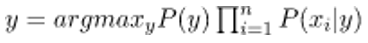
So, ultimately, the job of calculating P(y) and P (xi | y) is left.
Please note that P(y) is also known as class probability and P (xi | y) is known as conditional probability.
Gaussian Naive Bayes classifier
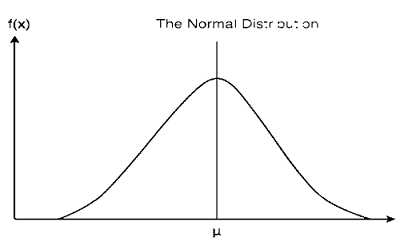
In Gaussian Naive Bayes, continuous values associated with each feature are assumed to be distributed according to a Gaussian distribution. A Gaussian distribution is also called Normal distribution. It gives a bell shaped curve when plotted, which is symmetrical with the mean of the function values as shown below:
The probability of the characteristics is assumed to be Gaussian, so the conditional likelihood is given by:
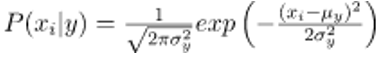
Gaussian Naive Bayes classifier implementation using sci-kit-learn
# load the iris dataset
fromsklearn.datasets import load_iris
iris = load_iris()
# store the feature matrix (X) and response vector (y)
X = iris.data
y = iris.target
# splitting X and y into training and testing sets
fromsklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1)
# training the model on training set
fromsklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
gnb.fit(X_train, y_train)
# making predictions on the testing set
y_pred = gnb.predict(X_test)
# comparing actual response values (y_test) with predicted response values (y_pred)
fromsklearn import metrics
print("Gaussian Naive Bayes model accuracy(in %):", metrics.accuracy_score(y_test, y_pred)*100)
Output:
Gaussian Naive Bayes model accuracy (in %): 95.0
Other common classifiers for Naive Bayes are:
Multinomial Naive Bayes: The frequencies at which a multinomial distribution has generated some events are represented by feature vectors. The event model is most commonly used for record classification.
Bernoulli Naive Bayes: Bernoulli Naive Bayes are a type of Bay In the multivariate Bernoulli event model, the features are independent booleans (binary variables) that represent inputs. This model is popular for document classification tasks, including the multinomial model, where binary term frequency (i.e. a word occurs in a document or not) functions are used instead of term frequencies (i.e. frequency of a word in the document).
Despite their oversimplified assumptions, naive Bayes classifiers have performed admirably in a variety of real-world scenarios, including document classification and spam filtering. They will need a small amount of training data to estimate the necessary parameters.
Naive Bayes learners and classifiers can be incredibly fast as compared to more advanced methods. The class conditional function's distributions are decoupled, which means that each distribution can be determined independently as a one-dimensional distribution. As a result, problems resulting from the curse of dimensionality are mitigated.
Advertisement
Advertisement