Home »
Python
5 Best Python Web Scraping Libraries
Python is famous for its huge varieties of packages and in this post, in this article, we will discuss the 5 best Python Web Scraping Libraries.
Submitted by IncludeHelp, on January 22, 2020
Well, there are tons of libraries available in python but these 5 are most used by people. You will know why most of the users are using these libraries.
The web is a huge data source and there are many ways to get data from the web. One of the most common ways is Scraping. There are different languages and in each language, there are multiple libraries that can be used to Scrap data on the web. This post is especially for python and its 5 best web scraping libraries.
Benefits of Scraping
Well, the web is a huge database for grabbing data. Nowadays, data is more costly then gold and the web is open for all to grab data. Here Scraping comes into play. With different scrapers and web scraping software, you can scrape data from the web. Many websites are running on Web Scraping.
One of the most useful websites I found which uses Scraping to get data is Price Trackers. This website Scrape the data from Amazon, Flipkart, Myntra, AJIO, ShoppersStop, etc and store them in a database. Later they use those data to show a price graph.
5 Best Python Web Scraping Libraries
- Requests
- Beautiful Soup 4 (BS4)
- lxml
- Selenium
- Scrapy
1) Requests
It is one of the most fundamental libraries for web scraping. Some people use URLLIB 2 or URLLIB3 instead of Requests.
Functions of Requests in Web Scraping:
It is used to get raw HTML data. On passing Web Page as a parameter you will get raw HTML of that page. Later this raw HTML can be used to get desired data from it.
It has many useful methods and attributes that could be useful in Scraping.
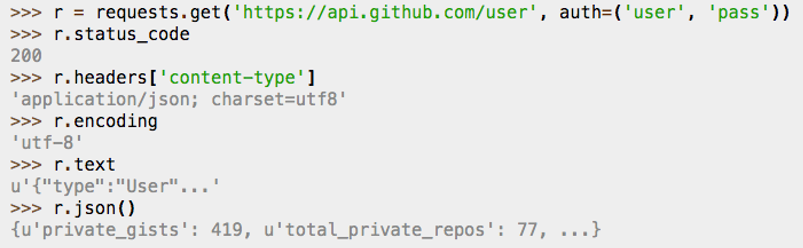
This above example of Requests.
Install
You can install this package from PyPI.
pip install requests
Run this command in your command prompt or Terminal.
Here is the Git Repository of this library. You can fork this to change according to your use.
2) Beautifulsoup4
One of the most famous python library for fetching data from HTML and XML. This library is for basic and simple use. You can do almost all the basic scraping things with beautiful-soup.
Main Functions of BS4
It is mainly used to fetch data from HTML or XML. Once you have raw HTML by using Requests library you can use this one to fetch useful data.

The above screenshot was taken from bs4 official documentation to show you its uses.
Install
you can install it via PyPI
pip install beautifulsoup4
Run the command in your terminal or cmd prompt.
Here is the official Documentation of BS4
3) LXML
This is one of the best parsers for HTML and XML. It is used to ease the handling of XML and HTML files. It is widely used for its simplicity and extremely fast response. This library is very useful in web Scraping as this can easily parse the large HTML or XML files.
Main Function of LXML
Lxml is used for parsing HTML or XML Files. It can parse even large HTML or XML files easily and fastly. That is why people use this parse while Scraping. It is required to parse the HTML or XML files. Some people use their own handwritten parser for parsing. But this parse is mostly used because of its speed, good documentation, the capability of parsing large files, etc.
Install
To install this via PyPI, run this command- pip install lxml
For more information on installation, you can check the documentation
4) Selenium
Selenium acts as a web driver. This API provides a way to use WebDriver like Firefox, Ie, Chrome, Remote, etc. A program can do almost all the tasks that can be performed by a user on web browsers like form fillings, form clicking or button clicking, browser opening and a lot more. It is a very useful tool in Python for web Scraping.
Main Function of Selenium:
It acts as a WebDriver and can perform tasks like browser opening, form filling, button clicking, etc.
Here is a Firefox WebDriver which is used to get information from python.org.
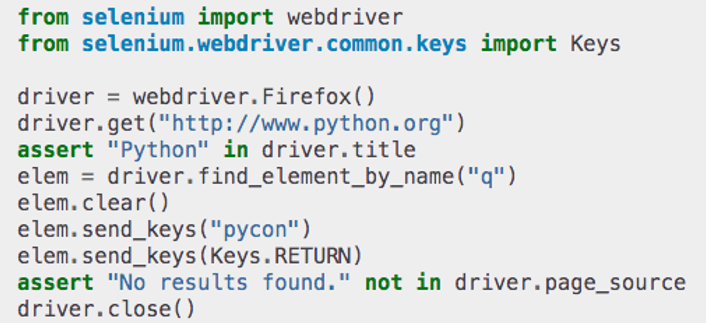
The above example is taken from Selenium's official documentation. In the above image, there is a basic use of Selenium. You can read further about the above example here.
Install
To install using PyPI, use this command- pip install selenium
Here is the official Git Repo for Selenium. You can fork this Repo to change the package according to your need.
5) Scrapy
Scrapy is a web scraping framework. It is one of the most advanced scraping framework available in Python. This Scrapy provides bots that can scrape thousands of web pages at once. Here you have to create a web spider that will go from one page to another and provides you the data.
Main Function of Scrapy:
With this Framework, you can create Spider that will crawl on web pages and scrape desired data from the web.
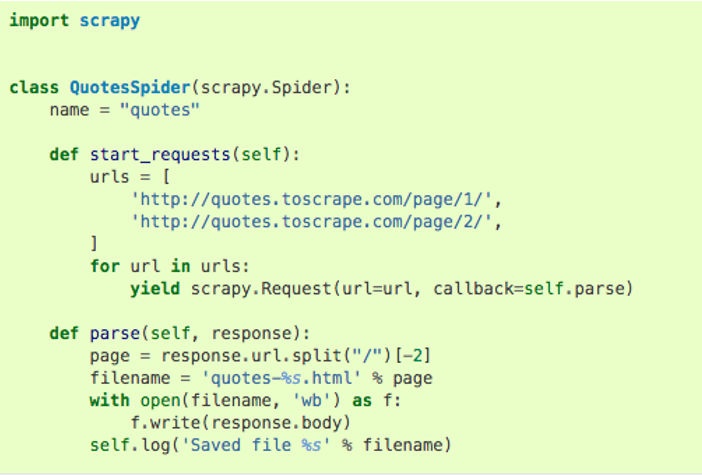
This is the basic code for creating a spider with Scrapy. There are tons of predefined class and methods and you just have to use them to create your Spider. It is easy to create a web Spider with this package. Rather it is quite difficult for a beginner to create a fully functional web scraper.
Install
To install using PyPI you can use this- pip install Scrapy
or
To Install Scrapy using conda, run this command- conda install -c conda-forge scrapy
Here is the installation guide for Scrapy. Also, check the documentation for Scrapy.
Advertisement
Advertisement