Home »
Python »
Python Programs
Pandas rank by column value
pandas.DataFrame.rank() Method: Here, we are going to learn how to rank a dataframe by its column value?
By Pranit Sharma Last updated : October 05, 2023
Pandas is a special tool that allows us to perform complex manipulations of data effectively and efficiently. Inside pandas, we mostly deal with a dataset in the form of DataFrame. DataFrames are 2-dimensional data structures in pandas. DataFrames consist of rows, columns, and data.
Problem statement
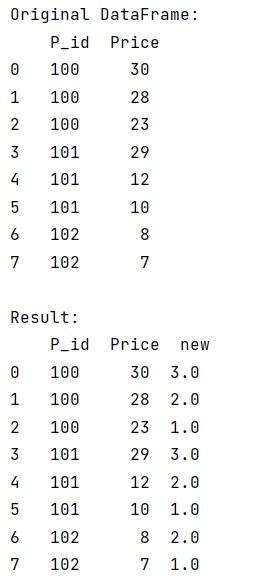
Suppose we are given a DataFrame that represent some product code and prices.
Here the dataframe is sorted by product id(ascending) and price(descending), we need to add a new column where the values are sorted based on product prices.
Pandas rank by column value
For this purpose, we will group the product id and price columns and apply the rank method on this object and pass the parameter ascending so that it will rank in ascending order.
The groupby() is a simple but very useful concept in pandas. By using groupby, we can create a grouping of certain values and perform some operations on those values.
The groupby() method split the object, apply some operations, and then combines them to create a group hence large amounts of data and computations can be performed on these groups.
Let us understand with the help of an example,
Python program to rank a dataframe by its column value
# Importing pandas package
import pandas as pd
# Importing numpy package
import numpy as np
# Creating a dictionary
d= {
'P_id':[100,100,100,101,101,101,102,102],
'Price':[30,28,23,29,12,10,8,7]
}
# Creating DataFrame
df = pd.DataFrame(d)
# Display dataframe
print('Original DataFrame:\n',df,'\n')
# Grouping and ranking
df['new'] = df.groupby('P_id')['Price'].rank(ascending=True)
# Display result
print("Result:\n",df)
Output
The output of the above program is:
Python Pandas Programs »
Advertisement
Advertisement