Home »
RDBMS
Data Abstraction in RDBMS
Here, we are going to learn about the data abstraction in RDBMS, and levels of the data abstraction.
Submitted by IncludeHelp, on November 08, 2020
Complex data structures are made up of database systems. The developers conceal internal, irrelevant information from users to ease user interaction with the database. This method of covering user information that is irrelevant is called data abstraction.
Three levels of abstraction exist:
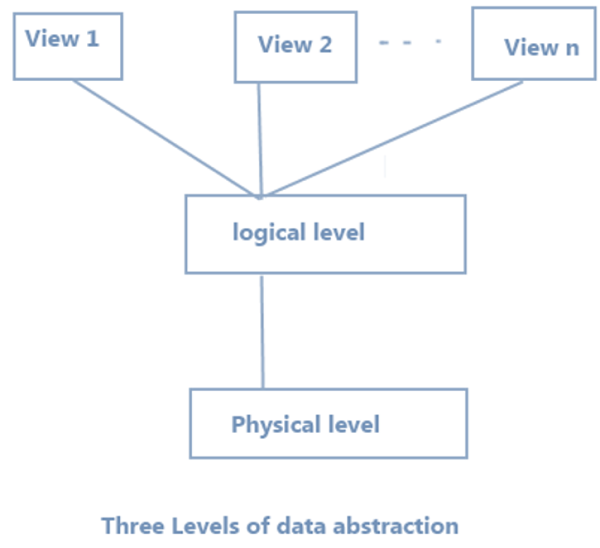
1) Physical: This is the lowest level of abstraction of knowledge. It tells us how memory is actually stored in the records. Access techniques such as sequential or random access and file structure techniques such as B+ trees are used for the same hashing. Usability, memory capacity, and the number of records are variables that we need to know when designing the database.
Suppose we need to store the information of an employee. Storage blocks and the amount of memory used for these purposes are kept secret from the user.
2) Logical: This stage consists of information in the form of tables that is currently contained in the database. It also stores in relatively simple structures the relationship between the data entities. The details available to the user at the view level is undisclosed at this level.
The different characteristics of an employee and relationships can be stored, e.g. with the manager.
3) View: This is the highest abstraction level. Users see only a portion of the real database. To ease the usability of the database by an individual user, this degree exists. Data is interpreted by users in the form of rows and columns. To store data, tables and relationships are used. There may be different views of the same database. Users may simply access the data and communicate with the database, shielding the specifics of storage and implementation from them.
Example: Let's assume we store customer data in a table of customers. These records can be represented at the physical level as storage blocks in memory (bytes, gigabytes, terabytes, etc.). The programmers also conceal these information from them.
These records can be represented at the logical level as fields and attributes along with their types of data, and their relationship between each other can be implemented logically. At this stage, programmers typically function because they are aware of certain things about database systems.
Users simply communicate with the device at view level with the aid of the GUI and enter the information on the computer, they are not aware of how the data is processed and what data is stored; they are shielded from those details.
Advertisement
Advertisement