Home »
Data Mining
Cluster Analysis: What It Is, Methods, Applications, and Needs in Data Mining
Data Mining | Cluster Analysis: In this tutorial, we will learn about the cluster analysis regarding data mining, methods of data mining cluster analysis, application of mining cluster analysis, etc.
By IncludeHelp Last updated : April 17, 2023
Why Clustering Analysis Is Used?
Data mining clustering analysis is used to combine data points with identical features in one group, i.e., data is partitioned into a group, collection by identifying correlations in objects in useful classes using various usable techniques (such as Density-based Method, Grid-based method, Model-based method, Constraint-based method, Partition based method, and Hierarchical method). Because of this function, it is commonly used in research to identify patterns, process images, and analyze data.
What is Cluster Analysis in Data Mining?
Clustering is the arrangement of data into similar groups. Unlike classification, class labels are undefined in clustering and it is up to the clustering algorithm to find suitable classes. Clustering is often called unsupervised classification since provided class labels do not execute the classification. Many clustering methods are based on the concept of maximizing the similarity (intra-class similarity) between objects of the same class and decreasing the similarity between objects in different classes (inter-class similarity).
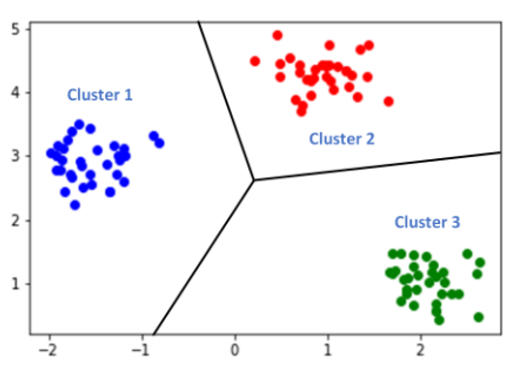
Fig 1: Example of clustering in data sets
In the above example, there are three different clusters. The data has arranged and grouped into the cluster as per the similarity features in the datasets.
Methods of Data Mining Cluster Analysis
There are in data mining a lot of ways in which clustering is conducted.
1. Hierarchical Method
Hierarchical Clustering is an unsupervised clustering algorithm that involves creating predominant clusters that have orders from top to bottom called Hierarchical cluster analysis or HCA. Hierarchical clustering is a group of clusters or groups in which each cluster is distinct from the other and each cluster's artifacts are broadly identical to each other.
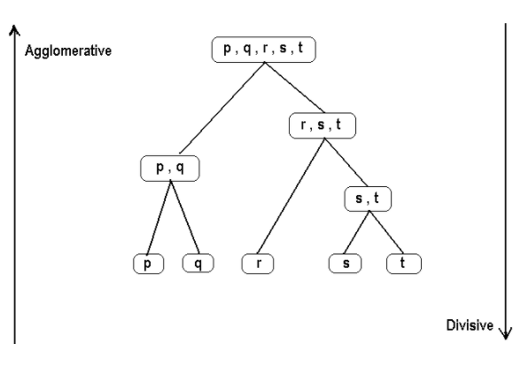
Fig 2: Example of hierarchical clustering in data sets
For example, files and directories on our hard drive are arranged in a hierarchy. With the algorithm, related artifacts are clustered into classes called clusters.
2. Partitioning Method
A data collection into a group of disjoint clusters is decomposed by partition clustering. A partitioning approach builds K (N ≥ K) partitions of the data, with each partition representing a cluster, given a data group of N points. That is, by meeting the following conditions, it classifies the data into K groups:
- Each group includes at least one point and
- Each point belongs to exactly one group. Here, a point will belong to more than one group for fuzzy partitioning.
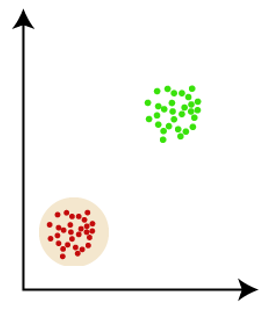
Fig 3: Example of partitioning clustering in data sets
Many algorithms for partition clustering aim to reduce an objective function. For eg, the function (also referred to as the distortion function) in K-means and K-medoids is ∑i=1K∑j=1|Ci|Dist(xj,center(i)).
3. Density-Based Clustering Method
Density-based clustering refers to unsupervised learning methods that define distinctive groups/clusters in the data based on the assumption that a cluster in data space is a contiguous region of high point density, isolated from other such clusters by contiguous regions of low point density. In this clustering approach in Data Mining, the primary emphasis is density.
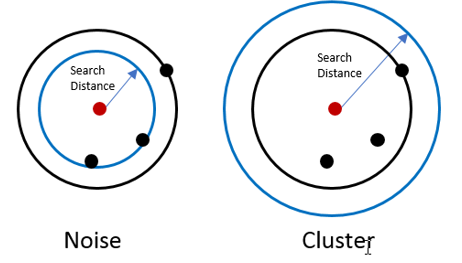
Fig 4: An example of Density-Based Clustering Method
As the basis for this clustering process, the notion of mass is used. The cluster will keep growing continuously in this clustering phase. There should be at least one point in the radius of the category for each data point.
4. Constraint-based Method
To execute the clustering, program or user-oriented constraints are implemented. The user's assumption is referred to as the constraint. In this method of classification, association, which is given by the constraints, is very interactive.
5. Model-based Method
Any cluster is hypothesized in this form of clustering system so that it can find the data that is a better fit for the model. In this process, the density function is clustered to locate the group.
6. Grid-based Method
In the Grid-Based Clustering Process, a grid is created using the combined entity. A Grid Structure is generated by quantifying the object space into a finite number of cells.
Application of Mining Cluster Analysis
Data clustering analysis has many uses, such as image processing, data analysis, recognition of patterns, market research and many more. Using data clustering, firms can discover new classes in the consumer database. Data grouping can also be achieved based on purchase patterns.
It helps to comprehend each cluster and its features. How the data is transmitted can be interpreted, and it serves as a method for data mining functions. There are a wide range of implementations in today's world cluster analysis,
- Cluster analysis is commonly used in market analysis, whether it is for pattern recognition, or image manipulation or exploratory data analysis.
- It lets advertisers find the various categories of their consumer base and they can use purchase habits to define their customer groups.
- Clustering analysis is used widely by financial institutions to detect fraud using clusters alongside outlier identification.
- It may be used in the field of biology to classify genes with the same capabilities by deriving animal and plant taxonomies.
- In the market, a consumer segment cluster is used to target the selling of various goods.
Needs of Clustering in Data Mining
- Scalability -We need highly efficient clustering algorithms to manage massive data groups.
- Discovery of clusters with attribute shape -The algorithm should be able to detect random clusters and should not be limited to distance measurements.
- Interpretability - The outcomes of clustering should be interpretable, descriptive, and accessible.
- High dimensionality -Instead of only handling low dimensional data, the algorithm should be able to handle high dimensional space.
- Ability to deal with different kinds of attributes - Algorithms should be able to be extended to any form of data, such as categorical, binary, and interval-based (numerical) data.
Advertisement
Advertisement