Home »
Data Mining
Data Cleaning in Data Mining
Data Mining | Data Cleaning: In this tutorial, we are going to learn about the data cleaning, its process and its benefits in data mining.
By IncludeHelp Last updated : April 17, 2023
What is Data Cleaning?
Data cleaning is a method to remove all the possible noises from data and clean it. Proper and cleaned data is used for data analysis and find key insights, patterns, etc from it. Data cleaning increases data consistency and entails normalizing of data.
The data derived from existing sources may be inaccurate, unreliable, complex, and sometimes incomplete. So, before data mining, certain low-level data has to be cleaned up. Data cleaning is not only about erasing data to make room for new information, but rather finding a way to improve the accuracy of a data set without actually deleting information.
Why Data Cleaning?
Data cleaning is important for both individuals and the organization. It accumulates a lot of data as the company expands. Clean and structured data allows the organization's executives and administrators to make decisions that will improve the organization's efficiency.
An effective organizational strategy assists organization retention for a long time. It makes the best choices, resulting in improved efficiency. To achieve more and more efficient data cleaning is important.
Data Cleaning Process
The data cleaning process handles data cleaning; but before handling the inconsistent data, it should be identified first. Following phases are used in the data cleaning process.
- Identify Inconsistent Details - Due to different factors, such as the data type, the discrepancy in data can be built with many optional fields that allow the candidates to fill in missing details. While entering the results, the candidates could have made a mistake. Any of the details might be out of date, such as updating address, phone number, etc. This may be the cause of the contradictory details.
- Identifying Missing Values - If there is a record that lacks several attributes and its values so that it can ignore.
- Remove Noisy Data and Missing Values - Noisy data incorporates information without meaning. For the expression of corrupt records, the term noisy information is also used. Noisy data cannot comply with valuable info by the data mining process. To allow data mining, noisy data increases the volume of data in the data warehouse that can be removed efficiently.
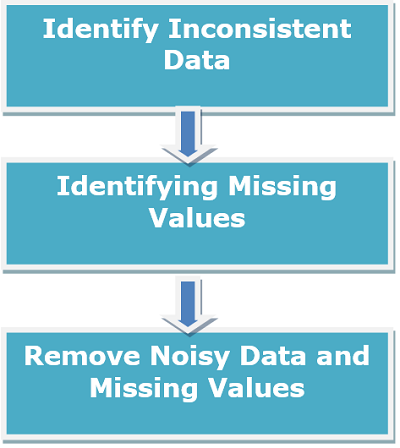
Fig: Data Cleaning Process
Overall following methods are used to eliminate noisy data -
- Cleaning - We may remove the noise by specifying boundary values to allow the substitution, based on how they are created.
- Regression - Regression is used for noisy data. Regression matches the data attributes as a feature that identifies the relationship between two variables, such as linear regression so that one attribute helps identify the value of another attribute.
- Clustering - The comparable data in a cluster is clustered by this method. The outliers can be undetected or outside of the clusters may collapse.
Benefits of data cleaning
- Removal of noises from various data sources.
- Error detection improves working efficiency and gives a direction to the users to identify mistakes come from various sources.
- Using the data cleaning process, we can get an effective business process and better decision-making.
Advertisement
Advertisement