Home »
Computer Architecture
Shared Memory Multiprocessor and Instruction Execution | Computer Architecture
In this tutorial, we are going to learn about the Shared Memory Multiprocessor and Instruction Execution in Computer Architecture.
Submitted by Uma Dasgupta, on March 04, 2020
Shared Memory Multiprocessor
There are three types of shared memory multiprocessor:
- UMA (Uniform Memory Access)
- NUMA (Non- uniform Memory Access)
- COMA (Cache Only Memory)
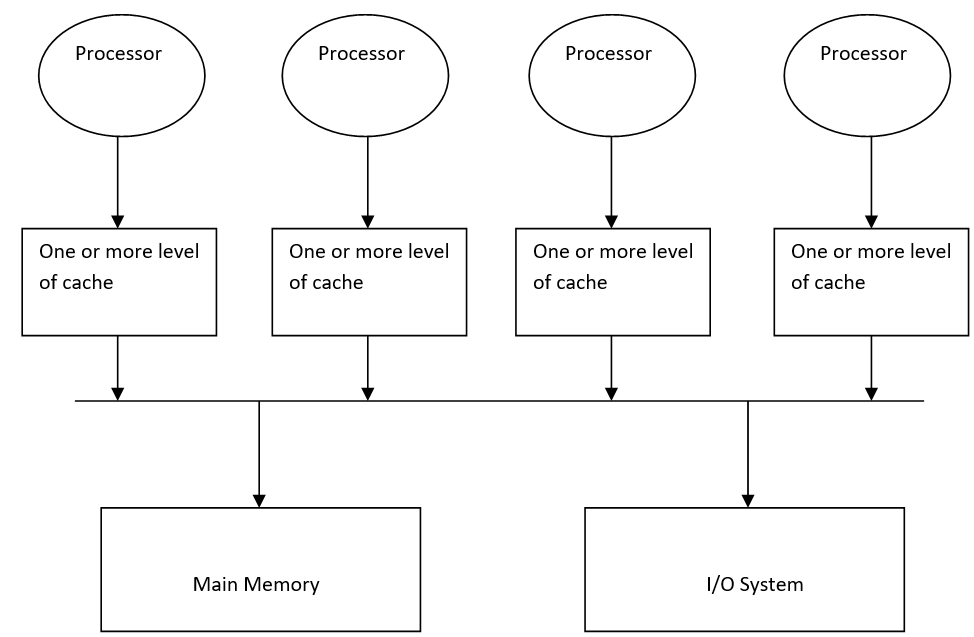
1) UMA (Uniform Memory Access)
In this type of multiprocessor, all the processors share a unique centralized memory so, that each CPU has the same memory access time.
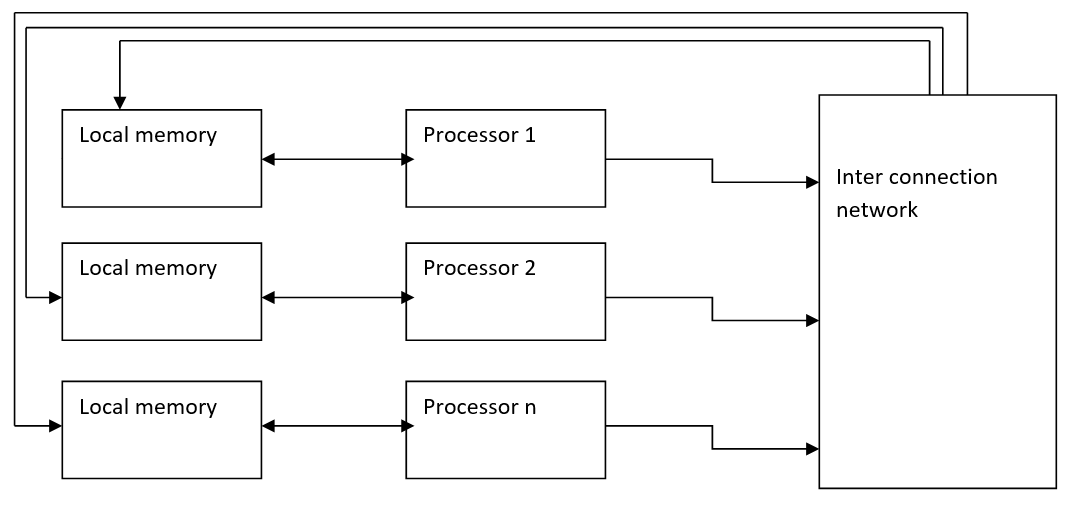
2) NUMA (Non- uniform Memory Access)
In the NUMA multiprocessor model, the access time varies with the location of the memory word. Here the shared memory is physically distributed among all the processors called local memories.
So, we can call this as a distributed shared memory processor.
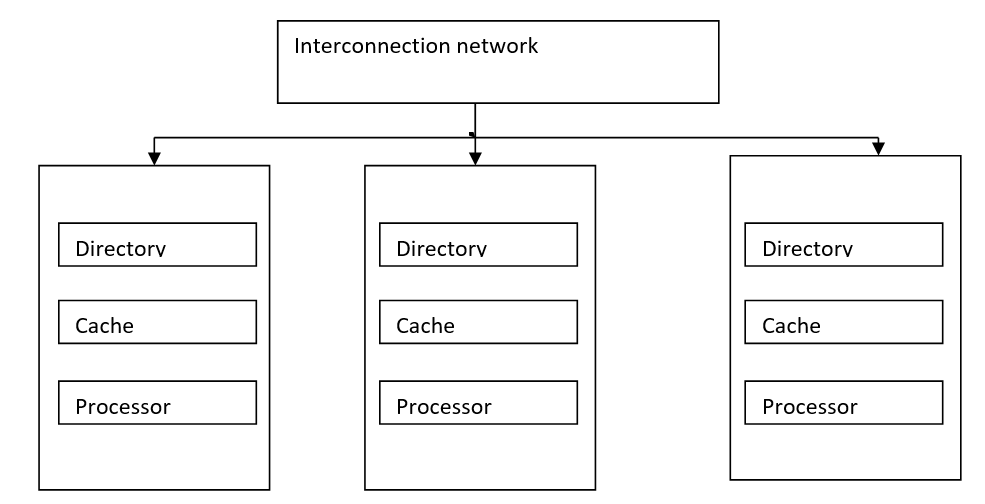
3) COMA (Cache Only Memory)
The COMA model is a special case of a non-uniform memory access model; here all the distributed local memories are converted into cache memories. Data can migrate and can be replicated in various memories but cannot be permanently or temporarily stored.
We have discussed different types of shared-memory multiprocessors. Now we are moving forward to take a short overview of instruction execution.
Instruction Execution
Now, first of all, what is an instruction, any command that we pass to a computer or system to perform is known as an instruction. A typical instruction consists of a sequence of operations that are fetched, decode, operand fetches, execute and write back. These phases are ideal for overlap execution on a pipeline.

There are two ways of executing an instruction in a pipeline system and a non-pipeline system.
In a non-pipeline system single hardware component which can take only one task at a time from its input and produce the result at the output.
On the other hand in case of a pipeline system single hardware component we can split the hardware resources into small components or segments.
Disadvantages of non-pipeline
- We process only one input at a single time.
- Production of partial or segmented output is not possible in the case of the non-pipeline system.
When you will read in deep about pipeline system you will discover pipeline are linear and non-linear also and further linear pipelines are also classified into synchronous and asynchronous.
As this article was only about the introduction of instruction execution so, we will get further inside the pipeline system.
Conclusion:
In the above article we have discussed the shared memory multiprocessor and introduction instruction execution, I hope you all have gathered the concepts strongly. For further queries, you shoot your questions in the comment section below.
Advertisement
Advertisement