Home »
Python »
Python Programs
Normalize dataframe by group
Let's understand how to calculate normalization on group by object?
Submitted by Pranit Sharma, on November 24, 2022
Pandas is a special tool that allows us to perform complex manipulations of data effectively and efficiently. Inside pandas, we mostly deal with a dataset in the form of DataFrame. DataFrames are 2-dimensional data structures in pandas. DataFrames consist of rows, columns, and data.
Problem statement
Suppose we have some data for which we create some categorization variable and using this data we create a dataframe.
Normalizing dataframe by group
To calculate normalization, we need to get the mean value per group, for this purpose, we will use the groupby() method.
The groupby() is a simple but very useful concept in pandas. By using groupby, we can create a grouping of certain values and perform some operations on those values.
The groupby() method split the object, apply some operations, and then combines them to create a group hence large amounts of data and computations can be performed on these groups.
After grouping, we will simply use the transform method inside which we will calculate the mean of each value of the dataframe group by object and divide it by the standardized value.
Let us understand with the help of an example,
Python program to calculate normalization on group by object
# Importing pandas package
import pandas as pd
# Importing numpy package
import numpy as np
# Creating dataframe
N = 10
m = 3
data = np.random.normal(size=(N,m)) + np.random.normal(size=(N,m))**3
ind = np.random.randint(0,3,size=N).astype(np.int32)
df = pd.DataFrame(np.hstack((data, ind[:,None])), columns=['A','B','C','ind'])
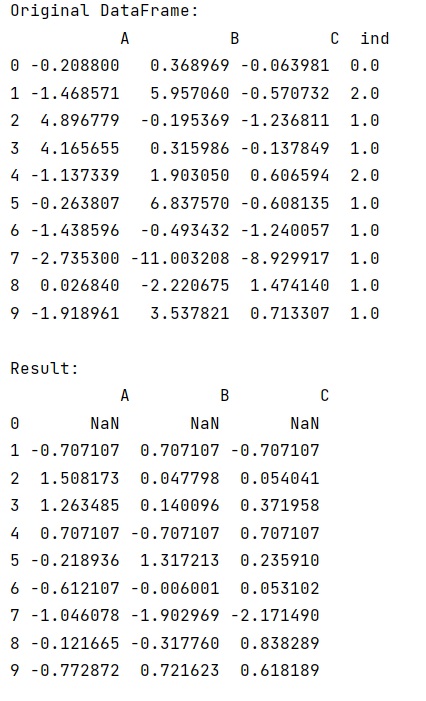
# Display original DataFrame
print("Original DataFrame:\n",df,"\n")
# Getting groupby and calculating normalization
res = df.groupby('ind').transform(lambda x: (x - x.mean()) / x.std())
# Display result
print("Result:\n",res,"\n")
Output
Python Pandas Programs »
Advertisement
Advertisement