Home »
Python »
Python Programs
Calculate average of every x rows in a table and create new table
Given a pandas dataframe, we have to calculate average of every x rows in a table and create new table.
Submitted by Pranit Sharma, on October 11, 2022
Pandas is a special tool that allows us to perform complex manipulations of data effectively and efficiently. Inside pandas, we mostly deal with a dataset in the form of DataFrame. DataFrames are 2-dimensional data structures in pandas. DataFrames consist of rows, columns, and data.
Problem statement
Given a Pandas DataFrame (we can consider is as a table), we have to Calculate average of every x rows in a table and create new table.
Calculating average of every x rows in a table and create new table
For this purpose, we will use the pandas.DataFrame[col].Mean(), this function returns mean of the specified column of the DataFrame. Where, Mean is nothing but an average value of a series of a number. Mathematically, the mean can be calculated as:
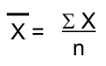
Here, x̄ is the mean, ∑x is the summation of all the values and n is the total number of values/elements.
Example of Mean
Suppose we have a series of numbers from 1 to 10, then the average of this series will be:
∑x = 1+2+3+4+5+6+7+8+9+10
∑x = 55
n = 10
x̄ = 55/10
x̄ = 5.5
Note (1)
In pandas, we use pandas.DataFrame['col'].mean() directly to calculate the average value of a column.
Note (2)
To work with pandas, we need to import pandas package first, below is the syntax:
import pandas as pd
To work with Python NumPy, we need to import numpy package first, below is the syntax:
import numpy as np
Here, we are going to group every x rows and then we will find the mean of these values.
Let us understand with the help of an example,
Python program to calculate average of every x rows in a table and create new table
# Importing pandas package
import pandas as pd
# Importing numpy package
import numpy as np
# Creating a dictionary
d = {
'a':[2,4,6,8,10],
'b':[1,3,5,7,9],
'c':[2,4,6,8,10],
'd':[1,3,5,7,9]
}
# Creating DataFrame
df = pd.DataFrame(d)
# Display original DataFrame
print("Original DataFrame:\n",df,"\n")
# Calculating mean
res = df.groupby(np.arange(len(df))//2).mean()
# Display result
print("Result:\n",res)
Output

Python Pandas Programs »
Advertisement
Advertisement