Home »
Big Data
Introduction to Hadoop and its Physical Architecture
Submitted by Uma Dasgupta, on September 08, 2018
What is Hadoop?
"Hadoop is an open source software framework which provides huge data storage".
Now, from the definition, we can see that Hadoop is open source now the people who are from tech field can easily understand that what open field, is means we don’t need to pay for using it, its free anybody can access it.
Now, comes software framework, means Hadoop is not a software it is a software framework, like for example we can say java, java is not a software it’s a software platform, like the cloud, google cloud they all are platforms they are not software, from anywhere you can access them.
Basic Diagram of Hadoop
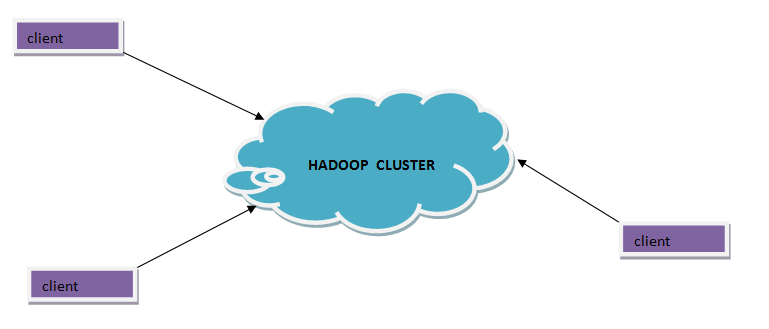
Now, the above shown is the basic diagram of Hadoop, you can see I represented it by a cloud shape, and it’s working is also shown as that there are no. of clients accessing it and in between there is a cluster, cluster means it cannot be on one machine it is located on multiple machines.
Basic Components of Hadoop
- Name Node (NN)
- Job Tracker (JT)
- Secondary Name Node (SNN)
- Task Tracker (TT)
Physical Architecture of Hadoop
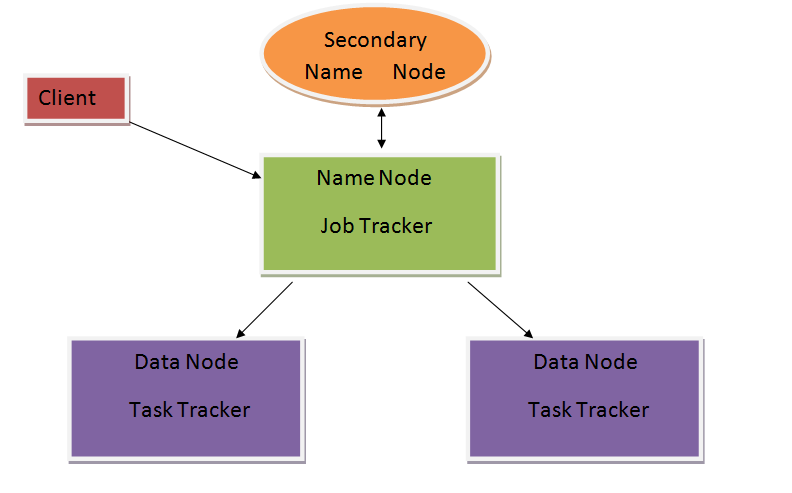
Note: There is no fixed number of data nodes, it can be as much as required or made.
Working
When the client will submit his job, it Will go to the name node, now name node will decide whether to accept the job or not. After accepting the job, the name node will transfer the job to the job tracker, job tracker will divide the job into components and transfer them to data nodes now data nodes will further transfer the jobs to the task tracker, now the actual processing will be done here, means the execution of the job submitted is done here. Now, after completing the part of the jobs assigned to them, the task tracker will submit the completed task to the job tracker via the data node. Now, coming on secondary name node, the task of secondary name node is to just monitor the whole process ongoing.
Note: The job tracker continuously communicates with the task trackers in the case in any moment job trackers do not get a reply from any of the task trackers it considers that it failed and transfers its work to another one.
Now, physical architecture of Hadoop is a Master-slave process, here name node is a master, job tracker is a part of master and data nodes are the slaves.
Description of Hadoop Components
-
Name Node
- It is the master of HDFS (Hadoop file system).
- Contains Job Tracker, which keeps tracks of a file distributed to different data nodes.
- Failure of Name Node will lead to the failure of the full Hadoop system.
-
Data node
- Data node is the slave of HDFS.
- A data node can communicate with each other through the name node to avoid replication in the provided task.
- Data nodes update the change to the data node.
-
Job Tracker
- Determines which file to process.
- There can be only one job tracker for per Hadoop cluster.
-
Task Tracker
- Only single task tracker is present per slave node.
- Performs tasks given by job tracker and also continuously communicates with the job tracker.
-
SSN (Secondary Name Node)
- Its main purpose is to monitor.
- One SSN is present per cluster.
Conclusion
In this article I tried to explain Hadoop and its physical architecture in a very simplified way, I hope I am able to make you understand Hadoop and its Physical architecture clearly. For any further queries, you can shoot your questions in the comment section, I will surely try to answer them as soon as possible. Will be coming with new articles very soon. Till then stay connected, keep learning and stay updated!
Advertisement
Advertisement