Home »
DBMS
Data Replication in DBMS
DBMS | Data Replication Tutorial: In this tutorial, we will learn about data replication, its various types, features, advantages, and disadvantages in the database management system.
By Pratishtha Saxena Last updated : May 31, 2023
What is Data Replication in DBMS?
Data replication in a database management system (DBMS) refers to the process of creating and maintaining multiple copies of the same data in different locations or storage systems. It involves duplicating and synchronizing data across multiple nodes, servers, or sites to achieve goals such as improved availability, fault tolerance, performance, and data distribution.
In data replication, changes made to the original copy of data (known as the master or primary copy) are propagated to the replicated copies to ensure consistency. Replication can occur within a single database system (local replication) or across multiple database systems (distributed replication). The replicated copies are typically stored on different physical or logical devices to enhance data availability and reliability.
Types of Data Replication
Data replication can be implemented using various techniques which are discussed below:
1. Transactional Replication
Transactional replication focuses on replicating changes made at the transaction level. Each transaction executed on the primary copy is captured and propagated to the replicas, ensuring that all replicas maintain consistency with the primary copy in near real-time. Transactional replication requires efficient communication and synchronization mechanisms to ensure that the changes are applied in the same order at all replicas.
2. Snapshot Replication
Snapshot replication captures periodic snapshots of the primary database and distributes them to the replica nodes. These snapshots represent a point-in-time view of the data and are updated at regular intervals. Snapshot replication is suitable for scenarios where near-real-time synchronization is not required, and the replicas can tolerate some data staleness.
3. Merge Replication
Merge replication is commonly used in distributed or mobile computing environments. It allows multiple nodes or clients to independently modify their local copies of data, and later the changes are synchronized and merged into a consistent state. Merge replication handles conflicts that may arise when different replicas update the same data concurrently.
Data Replication Schemas
1. Full Replication
In full replication, all data from a source database is replicated to one or more destination databases. Every change made to the source database is replicated to all the replicas, ensuring that each replica has an identical copy of the entire dataset. Full replication provides high data availability, fault tolerance, and read scalability as each replica can serve read requests independently.
However, it can consume significant network bandwidth and storage resources, especially for large databases, and may introduce data consistency challenges in highly dynamic environments.
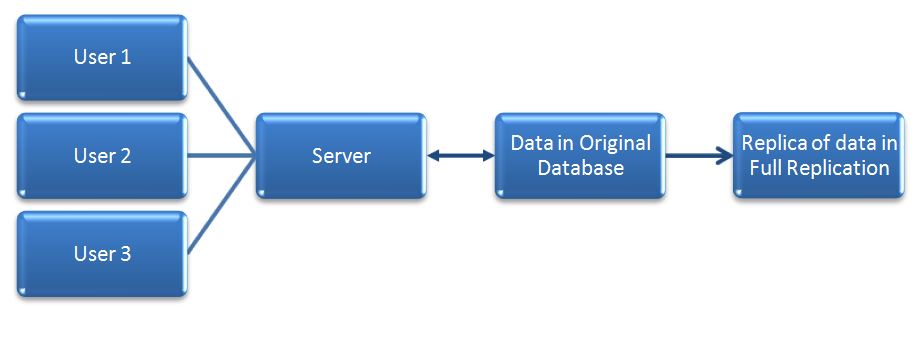
Advantages of Full Replication
- Data is highly available.
- Queries can be executed faster.
- Increase Performance.
Disadvantages of Full Replication
- Difficult to achieve the concurrency.
- Slow processing and execution time.
2. Partial Replication
Partial replication involves replicating only a subset of data from the source database to the destination databases. Rather than replicating the entire dataset, only selected tables, partitions, or specific data segments are replicated. This allows for more efficient utilization of network resources and storage, as only the necessary data is replicated. Partial replication is commonly used when specific subsets of data require higher availability or when certain data segments are accessed more frequently than others.
However, managing data consistency across the replicated subsets can be more complex compared to full replication.
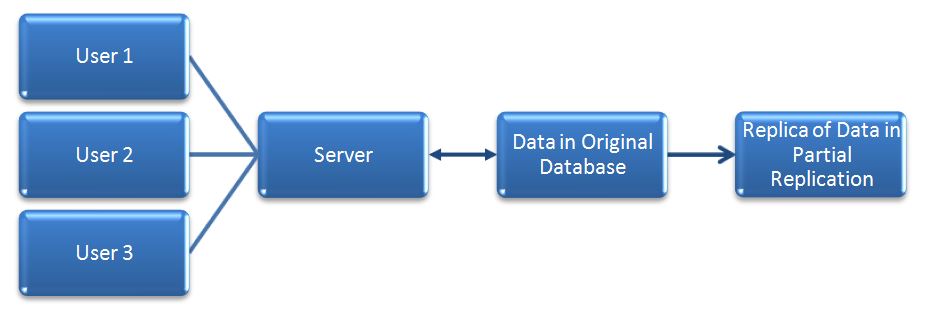
Advantages of Partial Replication
- Depending on the importance of the data, that much number of copies of the changed dataset is required.
3. No Replication
No replication refers to the absence of any data replication mechanism in the database system. In this scenario, changes made to the source database are not automatically propagated to any other databases or replicas. This approach may be suitable for certain scenarios where data replication is not necessary or where other mechanisms, such as backup and restore procedures, are employed to ensure data availability and disaster recovery.
However, it lacks the benefits of data redundancy, fault tolerance, and improved performance that replication can provide.
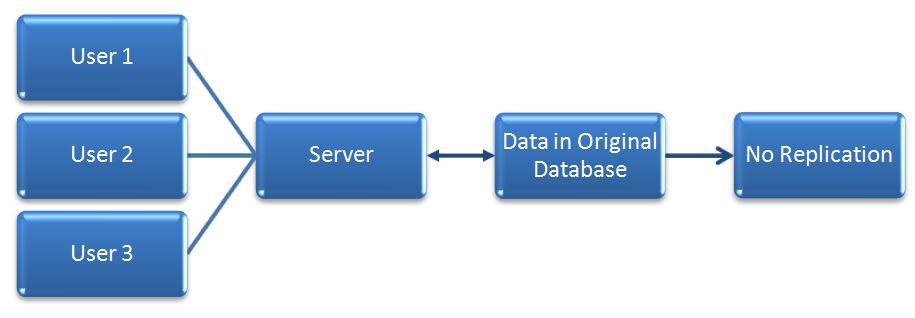
Advantages of No Replication
- Data can be recovered easily.
- Concurrency of the dataset can be minimized.
Disadvantages of No Replication
- Data availability gets poor.
- Slow processing and execution time, as on the same server, multiple accesses have been done.
The choice between full replication, partial replication, or no replication depends on various factors, including the desired level of data availability, fault tolerance requirements, network bandwidth limitations, scalability needs, and the trade-off between data consistency and performance. Each approach has its advantages and considerations, and the appropriate replication strategy should be determined based on the specific needs and characteristics of the application and database system.
Features of Data Replication
- High Availability: Data replication provides increased availability of data by creating redundant copies.
- Fault Tolerance: Replication enhances fault tolerance by maintaining multiple copies of data. If one copy becomes corrupted or unavailable, the remaining copies can be used for data recovery and to prevent data loss.
- Data Consistency: Data replication ensures that all copies of the data remain consistent. Changes made to the primary copy are propagated to the replicated copies.
- Performance Improvement: With replicated copies available at different locations, clients can access data from the nearest or most suitable replica, reducing network latency and improving response times.
- Scalability: Replication supports scalability by allowing multiple copies of data to handle concurrent read operations.
- Data Locality: Replication enables data to be stored closer to the users or applications that require it. This improves data access times, especially in distributed environments where users are geographically dispersed.
- Disaster Recovery: By maintaining replicated copies of data at separate locations, organizations can recover and restore data quickly in the event of a disaster or system failure.
- Load Balancing: Replication facilitates load balancing by distributing read operations across multiple replicas.
- Incremental Updates: This reduces network bandwidth requirements and improves replication efficiency.
- Consistency Models: Replication often supports different consistency models, allowing organizations to choose the level of consistency required for their applications.
Advantages of Data Replication
- Increased Data Availability
- Improved Performance
- Enhanced Fault Tolerance
- Disaster Recovery
- Scalability
- Geographical Distribution
- Local Data Access
Disadvantages of Data Replication
- Increased Complexity
- Data Consistency Challenges
- Storage Overhead
- Replication Lag
- Network Bandwidth Requirements
- Increased Complexity in Updates
- Higher Cost
Advertisement
Advertisement