Home »
Big Data Analytics
Apache Kafka: Its Components, Messaging System, API's
Apache Kafka: In this tutorial, we will learn about Apache Kafka, Its Components, Messaging system, APIs, etc.
By IncludeHelp Last updated : October 21, 2023
Apache Kafka
Apache Kafka is a distributed event streaming platform that is free and open source. It was first created by LinkedIn and is now an Apache Software Foundation project. It is made to handle processed data streams quickly, even if something goes wrong, and in real-time. Lots of people like Kafka, and many businesses use it to create reliable and scalable data streams, event-driven structures, and real-time data processing systems.
Following points summarizes Apache Kafka:
- The management of real-time data storage is handled by Apache Kafka, which is a stream-processing software platform that is available as open source.
- It acts as a middleman between two different parties, namely a sender and a recipient of the message. It is able to process around trillions of data events in a single day.
- Apache Kafka is a software platform that functions on the principle of a decentralised streaming procedure.
- It is a publish-subscribe messaging system that enables data to be shared between applications, servers, and processors in addition to being used for that purpose.
-
Initial development of Apache Kafka was by LinkedIn, and then company gave the project to the Apache Software Foundation. Confluent, which is part of the Apache Software Foundation, is currently responsible for its maintenance.
- The slow and cumbersome problem of data transfer between a sender and a receiver has been eliminated by Apache Kafka.
- It is a publish-subscribe messaging system that allows data sharing between applications, servers, and processors as well.
- Apache Kafka is a software platform that is built on a distributed streaming process.
- Apache Kafka has provided a solution to the sluggish problem that arises during data communication between a sender and a receiver.
Components of Apache Kafka
- Publish-Subscribe Messaging System: Kafka acts as a publish-subscribe messaging system where data is produced by publishers (producers) and consumed by subscribers (consumers). Producers send data to Kafka topics, and consumers subscribe to topics to receive and process the data.
- Topics: Kafka organises by topic. Data is released to designated channels or categories. Topics include data produced by producers and viewed by consumers. Data streams are logically separated by topics.
- Partitions: Partitions exist for each topic. Kafka distributes data horizontally between servers using partitions. The records in each division are sorted and unchangeable. They are Kafka's parallelism and scalability foundation.
- Brokers: Individual Kafka servers are termed brokers in this distributed architecture. Brokers maintain topic divisions and process producer and consumer requests. Multiple brokers are used in Kafka clusters for fault tolerance and scalability.
- Producers: Kafka topics receive data from producers. They write data to topics, and Kafka distributes it across partitions.
- Consumers: Consumers read Kafka data. Subscribe to subjects and process data in real time. Multiple readers can read the same Kafka topic in tandem.
- Zookeeper: Previously, Kafka managed brokers distributedly with Apache ZooKeeper. Since Kafka 2.8.0 (my knowledge cutoff date), it has started replacing ZooKeeper with its built-in consensus protocol to reduce dependency on external services.
- Connectors: Kafka Connect simplifies integration with other data sources and sinks (databases, file systems, etc.). Connector plugins enable data intake and egress.
- Streams: Kafka Streams is a library for real-time data processing applications that process Kafka topics and provide results to Kafka or other systems. It supports stream processing and event-driven micro-services.
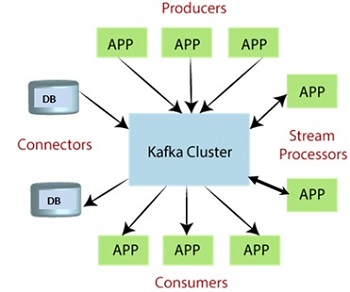
Messaging System in Kafka
Apache Real-time data pipelines and streaming applications employ Kafka, a distributed streaming platform. It supports high throughput, fault tolerance, and scalability. Kafka is best known for event streaming and data intake, but it may also be used to develop a messaging system.
- The act of exchanging messages between two or more parties (people, equipment, etc.) is what constitutes a messaging system.
- A publish-subscribe messaging system gives a sender the ability to transmit and write messages, while also giving receivers the ability to read those messages.
- In Apache Kafka, a sender is referred to as a producer when they publish messages, and a receiver is referred to as a consumer when they subscribe to that message in order to consume it. Producers publish messages.
To initiate the process we follow following steps -
Topic Creation:
In Kafka, messages are organized into topics. Topics act as channels or categories where messages are published and consumed. We can create topics using the Kafka command-line tools or programmatically using Kafka APIs.
# Create a topic named "sample topic"
bin/kafka-topics.sh --create --topic sample-topic --bootstrap-server localhost:
Producers: Producers sends messages to Kafka topics. You can create producer applications in your preferred programming language (Java, Python, etc.) using Kafka client libraries.
Consumers: Consumers receives messages from Kafka topics. User can create consumer applications using Kafka client libraries.
Message Processing: Messages published to Kafka topics can be processed in real-time by consumers.
Fault Tolerance: Kafka provides fault tolerance by replicating data across multiple brokers.
Data Retention and Cleanup: Kafka allows you to configure data retention policies, which determine how long messages are retained in a topic.
Security: Kafka supports security features like SSL/TLS encryption, authentication, and authorization to protect users messaging system from unauthorized access.
Integration: A user can integrate Kafka with other systems and technologies, such as Apache Spark, Apache Flink, Elasticsearch, and more, to build complex data processing pipelines.
Streaming Process
- The processing of data in several parallelly connected systems is referred to as a streaming process. This procedure makes it possible for various applications to restrict the processing of data in parallel, which means that one record may be processed without waiting for the output of the record that came before it.
- As a result, the user may simplify the job of the streaming process and execute concurrent tasks while using a platform that supports distributed streaming. Because of this, a streaming platform in Kafka is equipped with the following essential features:
- As soon as the streams of records occur, it processes it.
- It works similar to an enterprise messaging system where it publishes and subscribes streams of records.
- It stores the streams of records in a fault-tolerant durable way.
Apache Kafka API's
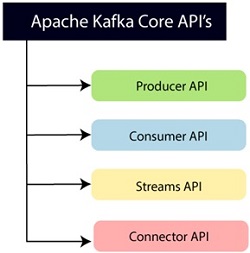
- Producer API: An application is able to publish streams of records to one or more topics using this application programming interface (API).
- Consumer API: With the help of this application programming interface (API), a programme may subscribe to one or more topics and then handle the stream of records that is produced to them.
- Streams API: With the help of this application programming interface (API), a programme may successfully transform the input streams into the output streams. It makes it possible for an application to perform the functions of a stream processor, consuming an input stream coming from one or more topics and producing an output stream that may be sent to one or more output topics.
- Connector API: This application programming interface (API) allows current data systems or applications to run reusable producer and consumer APIs.
Advertisement
Advertisement