Home »
Big Data Analytics
How MapReduce Works?
Working of MapReduce: In this tutorial, we will learn how MapReduce works, and its various states with the help of examples.
By IncludeHelp Last updated : July 01, 2023
MapReduce is a programming model and framework designed to process and analyzes large volumes of data in a distributed computing environment. It is a programming model for the parallel processing of large quantities of structured, semi-structured, and unstructured data on large clusters of commodity hardware. The process of computation is simplified with the use of a parallel and distributed algorithm on a cluster. It is possible to manage large amounts of data by using MapReduce in conjunction with HDFS[1].
In MapReduce, a "key, value" pair serves as the fundamental informational building block. Before feeding the data into the MapReduce model, all of the different forms of structured and unstructured data need to be transformed into this fundamental unit. As the name of the model indicates, the MapReduce model is made up of two distinct procedures, which are referred to as the Map-function and the Reduce-function. In the MapReduce paradigm, the computing that is performed on an input (that is, on a set of pairs) occurs in three steps, namely Map, Shuffle, and Reduce.
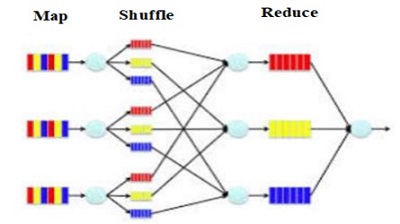
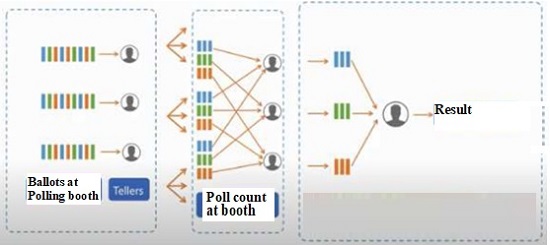
Following example demonstrates working of MapReduce-

Step 1: The map stage
The map and shuffle phases distribute the data semantically, whereas the reduce phase executes the computation. During the mapping process, the incoming data is parsed into smaller pieces that may then be processed in parallel by the cluster's various computing nodes. Data is transformed into key-value pairs at each computing node by using a mapping function. Unlike other data frameworks, MapReduce logic is not limited to structured datasets. It has extensive unstructured data processing capabilities. The critical phase that makes this possible is the mapping stage. Mapper provides structure to data that is unstructured.
Example
It is necessary for me to analyze unstructured data if I want to count the number of images stored on my laptop according to the place (city) where the photograph was shot.
From this data source, the mapper generates pairs consisting of a key and its associated value. In this scenario, the location will serve as the key, while the snapshot will serve as the value. When the mapper has finished its job, we will have a structure for the complete data set. During the map step, the mapper accepts as input a single key-value pair and generates any number of key-value pairs as output.
It is essential to consider the map operation to be stateless; this means that its logic works on a single pair at a time. To briefly summarise, during the map phase, the user just writes a map function that maps an input (key, value) pair to any number (including none) of output pairs. The majority of the time, the map phase is used to do nothing more than change the key of the input value to define where the value should be placed.
Step 2: The shuffle stage
The shuffle step is automatically handled by the MapReduce framework, in this phase the values related to each key must be gathered in one place. All the intermediate values for a particular key will be delivered to the same reducer node once they have been shuffled and sorted.
Step 3: The reduce stage
In this phase, the reducer is responsible for taking all of the values that are connected to a single key k and producing any number of key-value pairs. The reducer is able to carry out computations in sequential order on the data since it has access to all the values that have the same key. The results generated by the "map" stage are aggregated and combined to produce the final output.
In this phase, a group of reducer nodes works on the key-value pairs that were created in the previous phase. Each reducer node processes the key-value pairs that share the same key using a reduction function. Depending on the nature of the problem, the reduction function may perform actions like aggregation, filtering, or summarization. Reduce produces a set of completed key-value pairs.
The user is responsible for designing a function for the reduction phase of the process. This function must accept as its input a list of values associated with a single key and must output any number of pairs, most of the time, the output keys of a reducer are the same as the input keys.
There are many different techniques to carry out MapReduce tasks, including the following:
- The conventional method, which involves employing the Java MapReduce program to process structured, semi-structured, and unstructured data.
- The scripting technique for MapReduce that makes use of Pig to handle structured and semi-structured data.
- The Hive Query Language (also known as HQL or HiveQL[2]), which is used for processing structured data with Hive and MapReduce.
Notes and References
- What is HDFS? - HDFS is a distributed file system that handles large data sets running on commodity hardware. It is used to scale a single Apache Hadoop cluster to hundreds (and even thousands) of nodes. HDFS is one of the major components of Apache Hadoop, the others being MapReduce and YARN.
- HiveQL - Hive provides the necessary SQL abstraction to integrate SQL-like queries (HiveQL) into the underlying Java without the need to implement queries in the low-level Java API.
Advertisement
Advertisement