Home »
Big Data Analytics
HDFS Architecture
HDFS Architecture: In this tutorial, we will learn about the Hadoop Distributed File System (HDFS) Architecture, its components, and major roles.
By IncludeHelp Last updated : July 09, 2023
A distributed file system called Hadoop Distributed File System (HDFS) is designed to run on commodity hardware to store and handle large volume of data among several Hadoop cluster nodes. It is a key component of Hadoop ecosystem and provides an effective and scalable solution for data processing and storage.
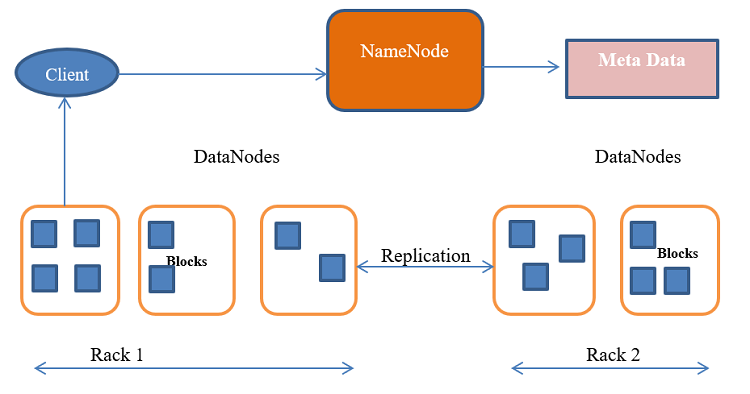
Fig: HDFS Architecture
HDFS Architecture
HDFS has master/slave architecture. It is highly fault-tolerant and deployable on low-cost hardware; provides high throughput access to application data and is suitable for applications that run on large quantities of data sets.
The architecture of HDFS consists of two main components: the NameNode and the DataNodes.
NameNode
An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In HDFS, the NameNode serves as the primary metadata management node. All of the files and directories are kept in the file system which is managed by it. File names, permissions, file hierarchy, and the placement of data blocks on DataNodes are the primary details included in the metadata. This data is stored in memory by the NameNode for quicker access. It also determines the mapping of blocks to DataNodes.
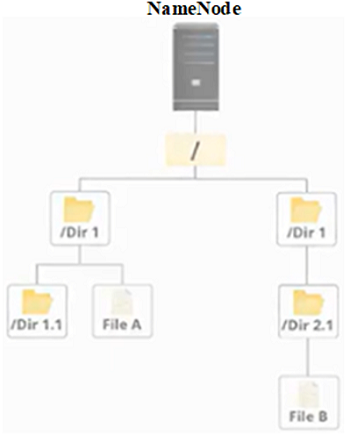
Fig: File Management Using NameNode
In HDFS, the NameNode is the single point of failure. To provide fault tolerance and prevent data loss, it is advised to employ a backup NameNode or Hadoop High Availability (HA) architecture.
DataNodes
DataNodes are slave nodes that store the real data. The DataNodes are responsible for serving read and write requests from the file system’s clients. A file is internally divided into one or more blocks, which are then stored in a collection of DataNodes. The data blocks work in accordance with the NameNode's instructions. Data storage is handled locally by each DataNode on a disc. For fault tolerance, the data is partitioned into fixed-size blocks with a default size of 128 MB and duplicated over many DataNodes.
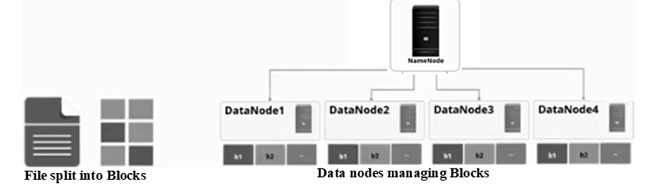
Fig: DataNode with Blocks
Upon direction from the NameNode, the DataNodes also handle block creation, deletion, and replication. The NameNode and DataNode are software components meant to run on commodity computers. There are several DataNodes, generally one for each node in the cluster, that handle storage attached to the nodes on which they execute. DataNodes communicate about a block to the NameNode. This information is used by the NameNode to monitor the cluster's status, control block replication, and execute load balancing.
The HDFS architecture is based on a master-slave model, with the NameNode acting as the master and the DataNodes acting as slaves, the NameNode manages metadata activities, whereas the DataNodes is responsible for data read and write operations. This delineation of duties enables scalability and effective data processing in parallel.
When a client program needs to read or write data, it communicates with the NameNode to find out where the data blocks are located. The client then talks directly with the necessary DataNodes to read or write the data. HDFS provides a streaming data access mechanism in which data is handled sequentially and batch-wise rather than randomly.
Overall, HDFS supports huge data storage and processing by providing fault tolerance, high availability, and scalability. It is well-suited for big data analytics tasks since it is optimized for processing massive files and streaming data.
HDFS Major Roles
The key roles of HDFS are as -
- Fault tolerance and reliability: To replicate file blocks and store them across nodes in a large cluster to ensure fault tolerance and reliability.
- High availability: Data replicates to other nodes; so, if the NameNode or a DataNode fails the data is available.
- Scalability: HDFS holds data on several cluster nodes; as demand grows, a cluster can scale to hundreds of nodes.
- High throughput: HDFS stores data in a distributed manner, allowing it to be processed in parallel across a cluster of machines. This, along with data proximity, reduces processing time and enables high throughput.
- Data locality: Instead of moving the data to where the computational unit resides, computation occurs on the DataNodes where the data resides. This strategy reduces network congestion and increases a system's overall throughput by minimizing the distance between the data and the computational process.
Advertisement
Advertisement