Home »
Big Data Analytics
Hadoop Ecosystem and Its Components
Hadoop Ecosystem and Its Components: In this tutorial, we will learn about the Apache Hadoop, Hadoop Ecosystem, and different applications integrated with Hadoop Ecosystem as its core components.
By IncludeHelp Last updated : June 09, 2023
Hadoop – An Overview
Hadoop is an open-source framework overseen by the Apache Software Foundation that is written in Java and used for storing and processing large datasets on a cluster of commodity hardware. Hadoop is managed by the Apache Software Foundation. The challenge with big data is mostly comprised of two components. The first is the storage of such a large amount of data, and the second is the processing of the data that has been saved.
- Due to the variability of the data, standard approaches such as relational database management systems (RDBMS) are insufficient.
- Hadoop is a solution to the problem of big data, which is the storing and processing of large amounts of data with the addition of some additional capabilities.
Hadoop Components
Hadoop is comprised mostly of three components: Hadoop Distributed File System (HDFS), Yet Another Resource Negotiator (YARN), and MapReduce.
1. Hadoop Distributed File System (HDFS)
HDFS is always faced with the challenge of dealing with massive data collections. It will be an understatement if HDFS is used to handle a large number of small data sets ranging in size from a few MB to several GB. High-Density File System (HDFS) architecture is constructed in such a way that it is well-suited for storing and retrieving massive amounts of data. What is required is a high cumulative data bandwidth as well as the ability to scale from a single node cluster to a hundred or a thousand-node cluster as needed. The ACID test requires that HDFS be able to manage tens of millions of files in a single instance, which is not always the case.
2. Yet Another Resource Negotiator (YARN)
As the name implies, Yet Another Resource Negotiator (YARN) is a resource manager who assists in the management of resources across clusters of computers. Briefly stated, it is responsible for the scheduling and resource allocation of the Hadoop System. It is made up of three fundamental components:
- Resource Manager
- Node Manager
- Application Master
3. MapReduce
MapReduce is the third component. When it comes to the Hadoop framework, MapReduce is a programming paradigm or pattern that is used to retrieve large amounts of data stored in the Hadoop File System (HDFS). It is a critical component of the Hadoop system, and its proper operation is essential.
MapReduce makes it possible to handle large amounts of data in parallel by breaking up petabytes of data into smaller chunks and processing them in parallel on Hadoop commodity computers. At the end of the process, it consolidates all of the data from many servers and returns it to the application as a consolidated result.
Hadoop Ecosystem
It is possible to think of the Hadoop ecosystem as integration of numerous components that are created directly on top of the Hadoop platform. There are, however, a plethora of complicated interdependencies across these systems to consider.
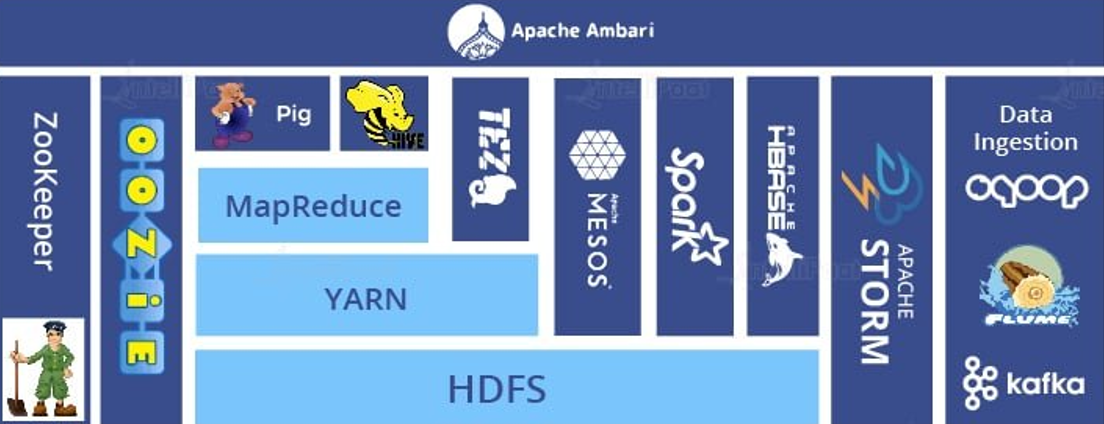
Fig: Hadoop Ecosystem [1]
Hadoop ecosystem includes: HDFS, YARN, MapReduce, Apache Pig, Apache Hive, Apache Ambari, Mesos, Apache Spark, Tez, Apache HBase, Apache Storm, Oozie, ZooKeeper, and Data Ingestion.
1. HDFS
A key data storage system for Hadoop applications, the Hadoop Distributed File System (HDFS), is the Hadoop Distributed File System. HDFS is a distributed file system that is implemented using NameNode and DataNode architecture to offer high-performance access to data across highly scalable Hadoop clusters.
2. YARN
Apache Hadoop's YARN component is responsible for assigning system resources to the various applications operating in a Hadoop cluster and scheduling jobs to be done on different cluster nodes. YARN is one of the main components of Apache Hadoop.
3. MapReduce
MapReduce works with two functions: Map and Reduce. The Map function accepts as input from the disc a set of key, value> pairs, processes them, and returns as output another set of intermediate key, value> pairs that were processed previously.
The Reduce function accepts inputs in the form of key, value> pairs and returns output in the form of key, value> pairs.
4. Apache Pig
Apache Pig is a very high-level programming API that allows us to write simple scripts. If we don't want to write Java or Python MapReduce codes and are more familiar with a scripting language that has somewhat SQL-style syntax, Pig is the best one.
5. Apache Hive
Hive is a means of accepting SQL queries and making the distributed data that is sitting on your file system look like a SQL database that is not actually there. It makes use of a programming language known as Hive SQL. In reality, it is merely a database in which you can connect to a shell client and ODBC (Open Database Connectivity) and perform SQL queries on the data that is stored on your Hadoop cluster, despite the fact that it is not a relational database in the traditional sense.
6. Apache Ambari
In order to make Hadoop management easier, the Apache Ambari project is developing software that will be used for deploying, managing, and monitoring Apache Hadoop clusters.
7. Mesos
Apache Mesos is an open-source cluster manager that manages workloads in a distributed environment by dynamic resource sharing and isolation. It is free and open-source software.
8. Apache Spark
Apache Spark is a multi-language engine that may be used to run data engineering, data science, and machine learning tasks on single-node workstations or clusters of computers.
9. Tez
A high-performance batch and interactive data processing framework, Apache Tez is managed by YARN in Apache Hadoop and is an extensible framework for constructing high-performance batch and interactive data processing applications. Tez enhances the MapReduce paradigm by significantly increasing its speed while retaining MapReduce's ability to scale to petabytes of data. Tez is currently in beta.
10. Apache HBase
HBase is a column-oriented data store that runs on top of the Hadoop Distributed File System and enables random data lookup and updates for large amounts of data. It is designed for big data applications. HBase creates a schema on top of the HDFS files, allowing users to read and alter these files as many times as they like.
11. Apache Storm
This is a system for the real-time processing of streaming data streams. Apache Storm extends the capabilities of Enterprise Hadoop by providing dependable real-time data processing. On YARN, a Storm is a strong tool for scenarios requiring real-time analytics and machine learning, as well as for continuous monitoring of operations.
12. Oozie
Apache Oozie is a Java Web application that is used to schedule jobs for the Apache Hadoop distributed computing system. Oozie integrates numerous jobs in a logical unit of labor by processing them in a sequential manner. With YARN serving as its architectural heartbeat, it is fully integrated with the Hadoop stack, and it supports Hadoop tasks for Apache MapReduce, Apache Pig, Apache Hive, and Apache Sqoop, among other technologies. Job scheduling software such as Oozie may also plan jobs that are specific to a system, such as Java programs or shell scripts.
13. ZooKeeper
Apache ZooKeeper is a Hadoop cluster management tool that provides operational services. Among other things, ZooKeeper provides a distributed configuration service, a synchronization service, and a naming registry for systems that are spread over multiple computers. Zookeeper is a distributed application service that stores and mediates updates to critical configuration information for distributed applications.
14. Data Ingestion
it involves bringing data from different sources or databases and files into Hadoop. Hadoop is free and open-source, and there is a multitude of methods for ingesting data into the system. It provides every developer with the option of ingesting data into Hadoop using her/his favorite tool or programming language. When selecting a tool or technology, developers place a strong emphasis on performance; yet, this makes governance extremely difficult.
Reference: Hadoop Ecosystem
Advertisement
Advertisement