Home »
Big Data Analytics »
Big Data Analytics MCQs
MCQs | Big Data Analytics – Fundamentals
Big Data Analytics Fundamentals MCQs: This section contains the Multiple-Choice Questions & Answers on Big Data Analytics Fundamentals with explanations.
Submitted by IncludeHelp, on December 27, 2021
Big Data Analytics Fundamentals MCQs
1. Data in ____ bytes size is called Big Data.
- Tera
- Giga
- Peta
- Meta
Answer: C) Peta
Explanation:
Big Data refers to data that is larger than a petabyte in size. The estimated volume of data that will be processed by Big Data solutions is significant and expected to continue to grow. In addition to increased storage and processing requirements, large data volumes necessitate the implementation of extra data preparation, curation, and management activities.
2. How many V's of Big Data?
- 2
- 3
- 4
- 5
Answer: D) 5
Explanation:
There are five V's of big data; these are Volume, Velocity, Variety, Value and Veracity. Knowing the 5 V's enables data scientists to extract more value from their data while also enabling the scientists' organizations to become more customer-centric as a result of their knowledge.
3. Unprocessed data or processed data are observations or measurements that can be expressed as text, numbers, or other types of media.
- True
- False
Answer: A) True
Explanation:
Unprocessed data or processed data are observations or measurements that can be expressed as text, numbers, or other types of media. In statistics, a data point, or observation, is a collection of one or more measurements taken on a single member of the observation unit (or unit of observation). Example: If the unit of observation is an individual and the research question is the determinants of money demand, a data point can be the values of income, wealth, the individual's age, and the number of dependents.
4. In computers, a ____ is a symbolic representation of facts or concepts from which information may be obtained with a reasonable degree of confidence.
- Data
- Knowledge
- Program
- Algorithm
Answer: A) Data
Explanation:
Information can be derived from data in computing if the data provides a symbolic representation of facts or concepts from which some probability can be calculated. While the summarizing of very large data sets might result in smaller data sets that are primarily composed of symbolic data, symbolic data are distinct in their own right on any sized data set, no matter how large or tiny it is.
5. In Big Data environments, Velocity refers –
- Data can arrive at fast speed
- Enormous datasets can accumulate within very short periods of time
- Velocity of data translates into the amount of time it takes for the data to be processed
- All of the mentioned above
Answer: D) All of the mentioned above
Explanation:
Large datasets can accumulate in a short amount of time in Big Data environments, since data arrives at lightning speed and accumulates in massive quantities. From the perspective of an enterprise, the velocity of data can be defined as the amount of time it takes for data to be processed once it enters the business's perimeter. In order to keep up with the rapid input of data, businesses must develop highly elastic and available data processing solutions, as well as the associated data storage capacities.
6. In Big Data environments, Variety of data includes –
- Includes multiple formats and types of data
- Includes structured data in the form of financial transactions,
- Includes semi-structured data in the form of emails and unstructured data in the form of images
- All of the mentioned above
Answer: D) All of the mentioned above
Explanation:
A wide range of data formats and kinds are required to be supported by Big Data systems, and this is referred to as data diversity. Enterprises have a number of issues when it comes to data integration, transformation, processing, and storage because of the variety of data. For example, financial transactions may contain structured data, while emails and photos may contain semi-structured data and unstructured data, respectively.
7. In Big Data environment, Veracity of data refers -
- Quality or fidelity of data
- Large size of the data that cannot be process
- Small size of the data that can easily process
- All of the mentioned above
Answer: D) All of the mentioned above
Explanation:
The quality or fidelity of data is referred to as veracity. Data entering Big Data environments must be evaluated for quality, which may necessitate data processing activities in order to resolve erroneous data and remove noise from the data stream. When it comes to authenticity, data can be either part of the signal or part of the noise of a dataset.
8. Which of the following are Benefits of Big Data Processing?
- Cost Reduction
- Time Reductions
- Smarter Business Decisions
- All of the mentioned above
Answer: D) All of the mentioned above
Explanation:
Cost reduction, time reductions and smarter business decisions are the benefits of big data processing.
9. Structured data conforms to a data model or schema and is often stored in tabular form.
- True
- False
Answer: A) True
Explanation:
Structured data is data that has been organized according to a data model or schema and is frequently kept in tabular format. Due to the fact that it is used to record relationships between distinct things, it is most typically kept in a relational database. Enterprise applications and information systems, such as ERP and CRM systems, are frequently responsible for the generation of structured data.
10. Data that does not conform to a data model or data schema is known as ______.
- Structured data
- Unstructured data
- Semi-structured data
- All of the mentioned above
Answer: B) Unstructured data
Explanation:
It is referred to as unstructured data when the data does not comply to a data model or a data schema. Unstructured data is believed to account for 80 percent of all data within a given organization, according to some estimates. The growth rate of unstructured data is faster than that of structured data. SQL cannot be used to process or query unstructured data since it is not structured. As a binary large object, it is saved in a table in a relational database if it is necessary to be stored within the database (BLOB).
11. Amongst which of the following is/are not Big Data Technologies?
- Apache Hadoop
- Apache Spark
- Apache Kafka
- Apache Pytarch
Answer: D) Apache Pytarch
Explanation:
Apache Pytarch is not a Big Data technology in the traditional sense. As part of a big data solution, Apache Hadoop, Apache Spark, and Apache Kafka are utilized. The Hadoop Distributed File System (HDFS) and a data processing engine that executes the MapReduce program to filter and sort data are the two primary components of Apache Hadoop. HDFS is a distributed file system that stores and distributes data across several computers. Apache Spark can also be used in conjunction with HDFS or another distributed file system. Hadoop MapReduce is capable of processing significantly larger data sets than Spark, particularly when the total size of the data collection exceeds the amount of memory that is available.
12. ______ involves the simultaneous execution of multiple sub-tasks that collectively comprise a larger task.
- Parallel data processing
- Single channel processing
- Multi data processing
- None of the mentioned above
Answer: A) Parallel data processing
Explanation:
Parallelism, which is defined in computing as the simultaneous execution of multiple processes, is the fundamental notion behind parallel data analysis. Parallel data processing is the simultaneous execution of several sub-tasks that together represent a bigger task in the context of a larger task. Parallel data analysis is a technique for analyzing data by running parallel processes on numerous computers at the same time.
13. Amongst which of the following can be considered as the main source of unstructured data.
- Twitter
- Facebook
- Webpages
- All of the mentioned above
Answer: D) All of the mentioned above
Explanation:
Unstructured data is primarily derived from social media platforms such as Twitter, Facebook, and the Internet. In the context of data storage, unstructured data refers to information that has not been organized according to a pre-determined data model or schema, and hence cannot be stored in a standard relational database management system (RDBMS). Text and multimedia are two types of unstructured content that are frequently encountered. Many business documents, as well as email messages, videos, images, webpages, and audio files, are unstructured in their content.
14. Amongst which of the following shows an example of unstructured data,
- Students roll number, age
- Videos
- Audio files
- Both B and C
Answer: D) Both B and C
Explanation:
Unstructured data includes files such as audio and video files, to name a few examples. In contrast to structured data, unstructured data does not fit well into a spreadsheet or database. It might be either textual or non-textual in nature. It can be created by a human or by a machine. Audio and video files, photos, text files - Word docs, PowerPoint presentations, email, chat logs, and other types of unstructured data are examples of unstructured data. Based on information gathered from social networking sites such as Facebook, Twitter, and LinkedIn Text messages, geolocation, chat, and call records are all examples of mobile data.
15. Scalability, elasticity, resource pooling, self-service, low cost and fault tolerance are the features of,
- Cloud computing
- Power BI
- System development
- None of the mentioned above
Answer: A) Cloud computing
Explanation:
Cloud computing is characterized by its scalability, elasticity, resource pooling, self-service, cheap cost, and fault tolerance, among other characteristics. While "Big Data" refers to massive volumes of data that have been collected, cloud computing refers to the technology that remotely receives this data and conducts any actions that have been specified on that information.
16. Amongst which of the following is/are the cloud deployment models,
- Public Cloud
- Private Cloud
- Hybrid Cloud
- All of the mentioned above
Answer: D) All of the mentioned above
Explanation:
Public Cloud, Private Cloud and Hybrid Cloud are the cloud deployment models. A cloud deployment model is characterized by the location of the infrastructure that will be used for the deployment and the authority that will be exercised over that infrastructure.
17. Virtualization separates resources and services from the underlying physical delivery environment.
- True
- False
Answer: A) True
Explanation:
Virtualization is the process of isolating resources and services from the physical delivery environment that they are delivered in. Big data virtualization is a method that focuses on the creation of virtual structures for large-scale data storage and processing environments. The usage of big data virtualization can be beneficial to businesses and other organizations because it helps them to make use of all of the data assets they have collected in order to achieve a variety of goals and objectives.
18. What is a Virtual Machine (VM)?
- Virtual representation of a physical computer
- Virtual representation of a logical computer
- Virtual System Integration
- All of the mentioned above
Answer: A) Virtual representation of a physical computer
Explanation:
A virtual machine (VM) is a representation of a physical computer that exists only in virtual space. In addition to a CPU, memory, and discs to store your stuff, it is capable of connecting to the internet if necessary. In contrast to the real and tangible components of your computer (referred to as hardware), virtual machines (VMs) are typically conceived of as virtual computers or software-defined computers that run on physical servers and exist solely as code.
19. In the given Virtual Architecture, name the missing layer,
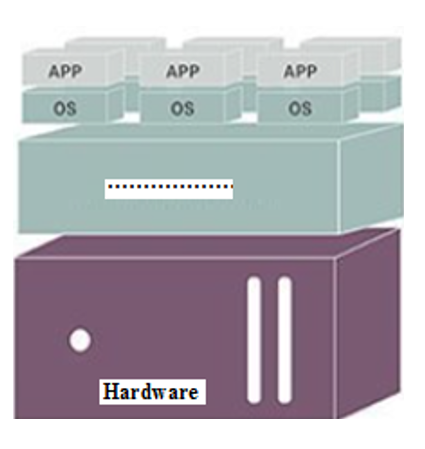
- Virtualization layer
- Storage layer
- Abstract layer
- None of the mentioned above
Answer: A) Virtualization layer
Explanation:
It serves as an additional abstraction layer between network and storage hardware, processing, and the application executing on that hardware.... A machine that has a virtualization layer can create other (virtual) machines, which can then be used to install alternative operating systems on top of the main machine.
20. MongoDB is a ____ database.
- SQL
- DBMS
- NoSQL
- RDBMS
Answer: C) NoSQL
Explanation:
MongoDB is a NoSQL (non-relational) database. Databases that are not tabular in nature, such as NoSQL databases, store data in a different way than relational tables. NoSQL databases are classified into a number of categories based on the data model they use. Document, key-value, wide-column, and graph are the four most common types. They are capable of supporting variable schemas and scaling quickly when dealing with big amounts of data and significant user traffic.
21. MongoDB support cross platform and is written in _____ language.
- Python
- C++
- R
- Java
Answer: B) C++
Explanation:
MongoDB is a cross-platform database that is created in the C++ programming language. MongoDB stores data as flexible, JSON-like documents, which means that fields can differ from document to document and that the data structure can be altered as the database matures. Because MongoDB is a distributed database at its heart, it comes with built-in features such as high availability, horizontal scaling, and geographic distribution that are simple to utilize.
22. Amongst which of the following is / are true to run MongoDB?
- High availability through built-in replication and failover
- Management tooling for automation, monitoring, and backup
- Fully elastic database as a service with built-in best practices
- All of the mentioned above
Answer: D) All of the mentioned above
Explanation:
It is necessary to have high availability with built-in replication and failover as well as management tooling for automation, monitoring, and backup. It is also necessary to have MongoDB running as a fully elastic database as a service with built-in best practices.
23. Big data deals with high-volume, high-velocity and high-variety information assets,
- True
- False
Answer: A) True
Explanation:
Big data is defined as information assets with a high volume, a high velocity, and a high variety of information assets that necessitate the use of cost-effective, creative types of information processing in order to get greater insight and make better decisions.
24. _____ hypervisor runs directly on the underlying host system. It is also known as "Native Hypervisor" or "Bare metal hypervisor".
- TYPE-1 Hypervisor
- TYPE- 2 Hypervisor
- Both A and B
- None of the mentioned above
Answer: A) TYPE-1 Hypervisor
Explanation:
TYPE-1 The hypervisor is a virtual machine that runs on top of the underlying host system. It is also referred to as a "Native Hypervisor" or a "Bare metal hypervisor" in some circles.
25. ____ is also known as "Hosted Hypervisor".
- TYPE-1 Hypervisor
- TYPE- 2 Hypervisor
- Both A and B
- None of the mentioned above
Answer: B) TYPE- 2 Hypervisor
Explanation:
The term "Hosted Hypervisor" refers to a TYPE-2 hypervisor that is hosted on a third-party server. Type 2 hypervisors are often encountered in setups with a modest number of servers, as the name suggests. The fact that we do not have to install a management console on another machine in order to set up and administer virtual machines is what makes them so convenient. All of this can be accomplished on the server where the hypervisor is installed. Hosted hypervisors are mostly used as management consoles for virtual machines, and we may do any activity with the help of the built-in functions of the hypervisor.
26. In the layered architecture of Big Data Stack, Interfaces and feeds,
- Internally managed data
- Data feeds from external sources.
- It provides access to each and every layer & components of big data stack
- All of the mentioned above
Answer: D) All of the mentioned above
Explanation:
Interfaces and feeds internally maintained data; data feeds from external sources; and offers access to each and every layer and component of the Big Data Stack are all included in the tiered design of the Big Data Stack. In order to create the Data Pipeline in accordance with the diverse requirements of either the Batch Processing System or the Stream Processing System, the Big Data Architecture is used. This architecture is made up of six layers, each of which is responsible for ensuring the secure transit of data.
27. _____ is the supporting physical infrastructure is fundamental to the operation and scalability of big data architecture.
- Redundant physical infrastructure
- Integrated System
- Integrated Database
- All of the mentioned above
Answer: A) Redundant physical infrastructure
Explanation:
It is critical for the functioning and scalability of big data architecture to have redundant physical infrastructure as a backbone of the infrastructure. Ideally, networks should be redundant and have sufficient capacity to handle the projected amount and velocity of inbound and outbound data, in addition to the "regular" network traffic encountered by the organization.
28. The physical infrastructure of a big data is based on a distributed computing model.
- True
- False
Answer: A) True
Explanation:
It is a distributed computing model that underpins the physical infrastructure of a big data system. The physical infrastructure will "make or break" the deployment of big data since it is concerned with high-velocity, high-volume, and high-variety data streams. The majority of big data deployments require high availability, which necessitates the use of resilient and redundant networks, servers, and physical storage systems. The concepts of resilience and redundancy are intertwined.
29. Security infrastructure refers the data about your constituents needs to be protected to ____.
- Meet compliance requirements
- Protect the privacy
- Both A and B
- None of the mentioned above
Answer: C) Both A and B
Explanation:
Security infrastructure refers to the data about your constituents that needs to be protected in order to comply with regulatory obligations and protect their personal information.
30. Reporting and visualization enables.
- Processing of data
- User friendly representation
- Both A and B
- None of the mentioned above
Answer: C) Both A and B
Explanation:
Reporting and visualization make it possible to process data and present it in a user-friendly manner. Putting data into a chart, graph, or other visual format that may be used to inform analysis and interpretation is known as data visualization (or data presentation). Different stakeholders can engage with and learn from data visualizations since they make the examined data easily understandable.
31. Data interpretation refers -
- Process of attaching meaning to the data
- Convert text into insightful information
- Effective conclusion
- All of the mentioned above
Answer: D) All of the mentioned above
Explanation:
Data interpretation is the process of giving meaning to information gathered from various sources. Interpretation entails drawing inferences about generalization, correlation, and causation, and it is designed to provide answers to critical learning questions regarding our research endeavor.
32. The significance of metadata is to provide information about a dataset’s characteristics and structure.
- True
- False
Answer: A) True
Explanation:
It is possible to obtain information about the qualities and structure of a dataset by using metadata. This sort of data is usually generated by machines and can be added to other types of data. The tracking of metadata is critical to Big Data processing, storage, and analysis because it offers information about the data's origins and provenance during processing, which is otherwise impossible to obtain.
33. Data throttling refers to the performance of a solution is throttled,
- True
- False
Answer: A) True
Explanation:
There are answers to the business difficulty, however on traditional technology, the performance of a solution is throttled as a result of data accessibility, data latency, data availability, or bandwidth limitations in relation to the size of the inputs.
34. The Big data analytics work on the unstructured data, where no specific pattern of the data is defined.
- True
- False
Answer: A) True
Explanation:
Big data analytics is used to analyze unstructured data, which is data that does not follow a predefined pattern and cannot be predicted. In this case, the information is not structured in rows and columns. The real-time flow of data is gathered, and analysis is performed on the data. When the amount of data to be analyzed is huge, efficiency increases.
35. Amongst which of the following represents the Use of Hadoop,
- Robust and Scalable
- Affordable and Cost Effective
- Adaptive and Flexible
- All of the mentioned above
Answer: D) All of the mentioned above
Explanation:
There are numerous advantages to implementing Hadoop. The following are some of the major advantages: robustness and scalability, affordability and cost effectiveness, adaptability and flexibility, as well as high availability and fault tolerance. In order to operate Hadoop, we do not require any specialized hardware. We can just utilize a commodity server for this purpose.
Advertisement
Advertisement