Home »
Big Data Analytics
What is Hadoop in Big Data? Components of Hadoop
Hadoop and Components of Hadoop: In this tutorial, we will learn about the Hadoop in big data and the various components of Hadoop with their subtypes and objectives.
By IncludeHelp Last updated : July 04, 2023
In this Big Data Hadoop tutorial, you will learn -
What is Hadoop?
"Hadoop is an open-source framework run by the Apache Software Foundation. It is written in Java and can store and handle large datasets using a cluster of inexpensive hardware in a distributed computing environment."
There are two main problems with "big data."
- The first is to store large-size data and process it.
- The standard methods, like RDBMS, are not capable to manage the heterogeneity of the data.
Hadoop is a feasible solution to solve the above-mentioned problems of big data. Hadoop can store and process a large amount of data with some extra capabilities; hence, Hadoop is beneficial for processing and analyzing massive amounts of structured, semi-structured, and unstructured data. Numerous industries and applications, including web analytics, log processing, recommendation systems, machine learning, and data warehousing, employ it extensively.
Hadoop Components
Followings are the main components of Hadoop:
- Hadoop Distributed File System (HDFS)
- Yet Another Resource Negotiator (YARN)
- MapReduce
1. Hadoop Distributed File System (HDFS)
HDFS is the main or most important part of the Hadoop ecosystem. It stores big sets of structured or unstructured data across multiple nodes and keeps track of information in log files. It is a distributed file system designed to store and manages a large amount of data across different Hadoop cluster servers. HDFS is a crucial component of the Apache Hadoop framework.
HDFS is commonly used in big data processing and analytics applications, in which large datasets are stored and processed across a cluster of devices. It has features scalability, fault tolerance, and high throughput, making it a well-liked option for managing large data workloads.
HDFS Components
HDFS consists of two core components i.e.,
NameNodes and DataNodes are the two primary components of HDFS's architecture. NameNode is responsible for managing file system metadata, including directory structure and file-to-block mapping. It maintains a record of which blocks reside on which DataNodes. Data nodes are responsible for holding the data units themselves.
Name Node
- The name node is also known as the master node which controls the workings of the data nodes.
- Generally, it contains metadata.
Data Node
- The main task of data nodes is to read, write, process, and replication of data.
- The data nodes communicate with NameNode using sending signals to the name node, known as heartbeats. These heartbeats show the status of the data node.
HDFS Cluster Master and Slave Nodes
Master and slave nodes form the HDFS cluster.
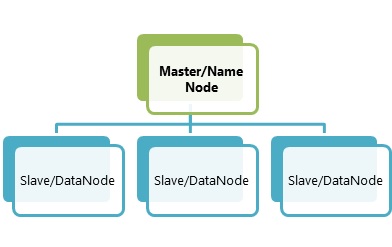
The master is the name node, and the slaves are the data nodes. The name Node is the main node. It saves metadata, which is information about data, and uses fewer resources than the data nodes, which store the real data. In a distributed environment, these data nodes are just like any hardware device which makes Hadoop cost-effective.
HDFS makes sure that the cluster and hardware devices work together; it can be considered the heart and soul of the Hadoop system. HDFS is designed to provide data access with high throughput and to assure fault tolerance and data integrity. It accomplishes this by dividing large files into smaller blocks and distributing them across the cluster's multiple servers. Typically, each block is replicated across three servers to provide redundancy and fault tolerance. The below-mentioned example demonstrates this using a well-structured diagram.
Example
Below image demonstrates the working of the Name node and Data Node,
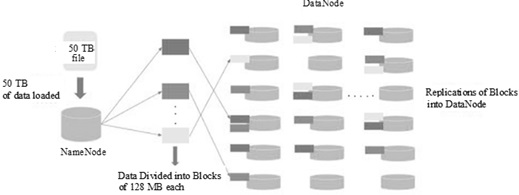
Let's consider 50 TB of data is put into the name node. It is sent to all of the data nodes by the name node, and this information is duplicated on all of the data notes. In the above image, we can see that the data are duplicated on each of the three data points.
By default, the files will be duplicated three times. This is done so that if a standard machine breaks down, you can swap it with a new machine that has the same data.
HDFS Objectives
1. Large Data Sets
HDFS has to work with big data sets all the time. It won't be enough to use HDFS to process a few small data sets that are MB or GB in size. HDFS is built in a way that makes it best for storing and retrieving large amounts of data.
With scalability features and high data bandwidth; it can spread out the files from a single node cluster to many clusters at the same time; hence, it can take care of tens of millions of files at the same time.
2. Write Once, Read Many Models
For its files and services, HDFS uses a method called "write-once, read-many." It thinks that a file in HDFS won't be changed after it's been written, even though it can be accessed 'n' times. At the moment, only one person can write to HDFS at a time. This assumption makes it possible to reach data quickly and makes problems with data coherency easier to solve. HDFS works best with a web crawler or a MapReduce program.
3. Streaming Data Access
As HDFS operates on the 'Write Once, Read Many' tenet, the capability of streaming data access is crucial. Given that HDFS is more suited to batch processing than to human interaction. High throughput data access is prioritized above low latency data access.
In HDFS, the emphasis is on how to obtain data as quickly as possible, particularly while analyzing logs. In HDFS, reading the entire set of data is more significant than how quickly a single item is fetched from the data. To achieve streaming data access, HDFS ignores a few POSIX (Portable Operating System Interface) restrictions.
4. Commodity Hardware
HDFS expects that the cluster(s) will run on common hardware, i.e., regular machines rather than high-availability systems. Hadoop has the advantage of being able to be put on any common commodity hardware. To work with Hadoop, we don't require supercomputers, this results in significant cost savings overall.
5. Data Replication and Fault Tolerance
HDFS operates with the idea that hardware will fail at some point in time. This interferes with the smooth and rapid processing of vast amounts of data. To circumvent this barrier, HDFS divides files into blocks of data and stores each block on three nodes: two on the same rack and one on a separate rack for fault tolerance.
A block is the amount of data that each data node stores. Although the default block size is 64MB and the replication factor is three, these settings can be changed per file. This redundancy provides resilience, failure detection, speedy recovery, scalability, reducing the requirement for RAID storage on hosts, and data localization benefits.
6. High Throughput
Throughput is the rate at which work is completed. It is commonly used as a performance metric and reflects how quickly data is being retrieved from the system. To do something in Hadoop HDFS, the effort is split up and distributed among several nodes.
All the systems will work concurrently and independently to complete their jobs. The time required to do the job is minimal. Throughput is improved in this manner using Apache HDFS. The time it takes to read data is cut drastically by using parallel processing.
7. Moving Computation is better than Moving Data
Hadoop HDFS is based on the idea that it is more efficient for applications to perform computations close to the data they operate on, especially when working with enormous data sets. The main benefit is higher throughput and less congestion in the network.
It is assumed that it is more efficient to move the computation to the location of the data rather than the data itself. This is made possible by the APIs provided by Apache HDFS, which allow applications to get closer to the data.
8. File System Namespace
HDFS uses a standard hierarchical file system, where any user or program may make folders and store files inside them. It is possible to create and remove files, move files from one directory to another, and rename files in HDFS, just as in any other file system. Generally, HDFS does not allow either hard links or soft links, although both may be added if necessary.
2. Yet Another Resource Negotiator (YARN)
YARN, short for "Yet Another Resource Negotiator," is a tool used to coordinate cluster-wide resource allocation. In a nutshell, it handles Hadoop's scheduling and resource allocation.
Hadoop 2.0 introduces YARN. Hadoop 1.0 uses a job tracker and many task trackers to complete a map-reduce process. Hadoop 1.0 has certain issues with scalability.
YARN Components
YARN consists of three major components i.e.,
- Resource Manager
- Nodes Manager
- Application Manager
Hadoop YARN functions as Hadoop's operating system. It's an additional file system that may be added to HDFS. Its job is to coordinate the cluster's resources so that no one node gets overworked. The jobs are planned appropriately thanks to the work scheduling it does.
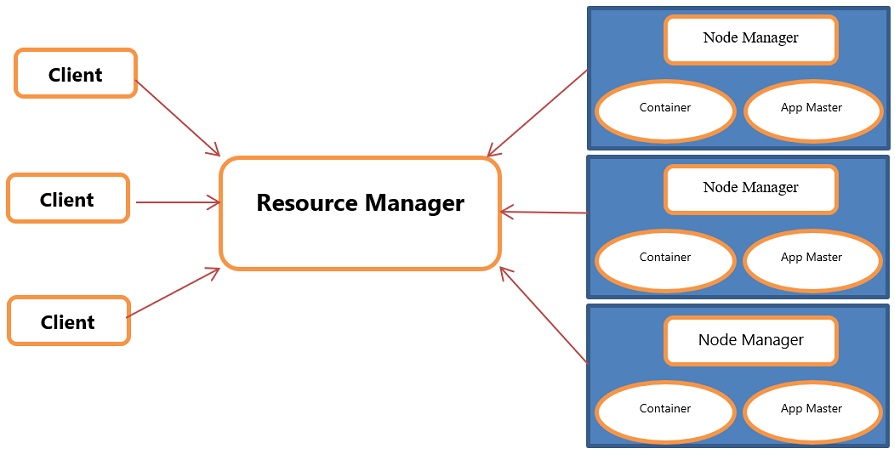
Client - A client refers to an entity that sends a task or application to the YARN cluster to run it. The client is typically a program or script running on a user's machine or a system that initiates the job execution.
Resource manager - The apps in a system can only receive the resources that the resource management has authorised them to get.
Node managers - Node Managers at each node allocate system resources like CPU, memory, and bandwidth before giving credit to the machine's resource management.
Application manager - The application manager acts as a go-between for the resource management and the node manager, negotiating resources and nodes as needed.
YARN Objectives
The objectives of YARN are as follows:
- Resource Management: The main goal of YARN is to manage and share resources in a distributed environment. It has a resource manager that keeps track of the resources that are available and allocates them to the different applications that are required resources dynamically running on the cluster. It makes sure that apps utilize resources efficiently.
- Scalability: Another goal of YARN is to make a platform that is very scalable and can handle large-scale groups and thousands of computers. It handles the cluster's resources and tasks in a way that makes it easy to grow and add more power.
- Compatibility: YARN is designed to be compatible with different applications and programming paradigms. It supports sequential processing and real-time processing frameworks, allowing developers to execute different types of workloads on the same cluster.
- Flexibility: YARN gives a flexible architecture that enables the execution of various application types on a shared infrastructure. It decouples resource management from application execution, allowing applications to be written in different programming languages and frameworks. This adaptability renders YARN an adaptable platform for executing a variety of duties.
- Availability: YARN's main goal is to make sure that the apps running on the cluster are always available. It makes sure that if a component fails, like a resource manager, the system can fix it and keep running normally. High uptime makes sure that apps work and keeps downtime to a minimum.
- Security: YARN has security tools that keep the cluster and all of its apps safe. It has methods for authentication and authorization, so only users with permission can access resources and send applications. YARN also keeps apps separate from each other to stop unauthorized entry or interference.
- Extensibility: YARN is made to be expandable, so coders can add new features and functions to meet different needs. It has a modular design that lets more resource schedulers, application frameworks, and tracking tools be added.
3. MapReduce
The core component of Hadoop is its MapReduce framework. The MapReduce distributes processing among the slave nodes, who then report their tasks to the master node. MapReduce utilizes distributed and parallel algorithms to make it feasible to develop applications that turn massive data sets into more manageable ones.
The complete dataset is processed by data with embedded code. In most cases, the amount of coded information is negligible compared to the raw data. To get a lot of work done on computers, we can just transmit a few thousand bytes of code.
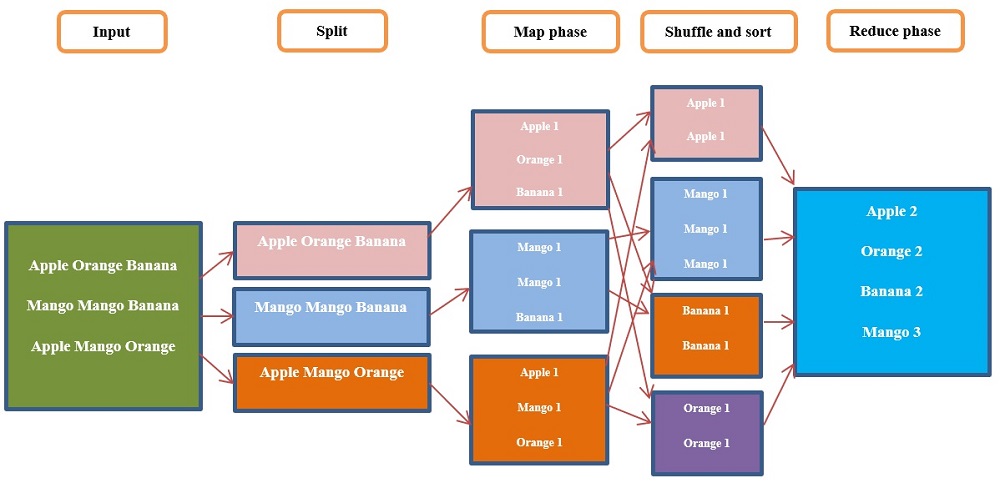
MapReduce makes use of two functions i.e. Map() and Reduce(). The description of these is described below.
MapReduce Components
The main components of MapReduce are:
- Input Data: Firstly data is inputted to the system that needs to be worked on. It can be inputted in different forms, like text files, in a database, or on HDFS.
- Split: The sets of intermediate keys and values are split up based on their names. Partitioning makes sure that all key-value pairs with the same key end up in the same partition. This step makes it easy to sort and group the data for the next phase.
- Map Function: the Map() function groups data by applying filters and performing sort operations on it. Using a key-value pair as input, Map produces a result that may be further processed using the Reduce() function. In a distributed computing framework, it uses multiple nodes to handle the data at the same time. The Map function gives you a set of intermediate key-value pairs as its result.
- Shuffle and Sort: The intermediate data that has been split up is sent from one node in the cluster to another. The key is used to sort the data so that all of the numbers that go with the same key are put together.
- Reduce Function: Reduce() is a basic function that takes the result of Map() as input and concatenates the tuples into a smaller collection of tuples. It aggregates the mapped data. Multiple nodes run the Reduce function at the same time, and its result is usually a set of final key-value pairs.
- Output Data: The result of the Reduce function is the result of the MapReduce process. It can be kept in different ways, like as text files, in a database, or on HDFS.
MapReduce Objectives
The primary objectives of MapReduce are as follows:
- Simplified programming model: MapReduce is a simple, high-level abstraction for distributed data processing. It hides the complicated parts of distributed computing, such as distributing data, keeping everything in sync, and handling errors. Without having to worry about low-level distributed system details, developers can focus on writing the map and reducing functions that describe the processing logic.
- Fault tolerance: MapReduce is designed in such a way that if a node fails in a distributed environment; the system detects it automatically and fixes the problem by moving the work to other nodes. Even if hardware or software fails, the "fault tolerance" system makes sure that the job gets done as a whole.
- Data locality: MapReduce makes data processing faster by reducing the amount of data that needs to be moved across the network. It does this by putting jobs on nodes where the data is already present. By managing data locally, MapReduce cuts down on network overhead and shortens the time it takes to move data, which improves speed overall.
- Flexibility: MapReduce is a system that can be used for different types of data processing jobs. It can work with structured, semi-structured, and unstructured data, as well as supports different programming languages. It allows developers to change the way it works by customizing their map and reducing functions. This makes it flexible for different uses.
Advertisement
Advertisement