Home »
Big Data Analytics
Big Data Architecture - Detailed Explanation & Components
Big Data Architecture: In this tutorial, we will learn about big data architecture, its definition, components, big data architecture processes, etc.
By IncludeHelp Last updated : June 09, 2023
The layout that serves as the foundation for big data systems is referred to as big data architecture. When it comes to big data architecture, it is designed to be arranged in a way that allows for the most efficient ingestion, processing, and analysis of data. Big Data gives a demonstration to users to get familiar with its environment and various working principles on which it deals. This tutorial describes the architecture of Big Data Analytics.
What is Big Data Architecture? Detailed Explanation
The architecture of big data serves as the framework for big data analytics. Large amounts of data must be managed before they can be analyzed for business objectives. It is the overall system that guides data analytics and creates an environment in which big data analytics tools may extract essential business information from otherwise unclear data.
As a reference blueprint for big data infrastructures and solutions, the big data architecture framework is used to define how big data solutions will work, the components that will be used, how the information will be transferred across systems, and other security considerations.
In order to realize the full potential of big data, it is critical to invest in a big data infrastructure that is capable of handling massive amounts of information. These advantages include: improving understanding and analysis of big data, making better decisions faster, reducing costs, predicting future needs and trends, encouraging common standards and providing a common language, and providing consistent methods for implementing technology that solves comparable problems. These advantages are not limited to:
Big data architecture should be structured in such a way that it can handle the ingestion process, data processing, and data analysis for data sets that are far too massive or complicated to be handled by typical database management systems. Varying organizations have different thresholds for their organizations; some have it set at a few hundred gigabytes, while others consider even a few terabytes to be a sufficient threshold figure. When you look at commodity systems and commodity storage, you will notice that the values and costs of storage have decreased dramatically as a result of this occurrence occurring. There is a tremendous amount of variability in the data, which necessitates alternative approaches to be taken. Some of them are batch-related data that arrives at a specific time, and as a result, the jobs must be scheduled in a similar manner, while others are streaming data, and as a result, a real-time streaming pipeline must be established in order to meet all of the requirements in real-time. Big data architecture provides a solution to all of these problems.
One of the biggest issues in big data infrastructure is managing data quality, which needs considerable analysis; scalability, which may be expensive and have a negative impact on performance if not done properly; and security, which becomes increasingly complex as data sets become larger.
Architecture for Big Data
Ingestion, processing, and analysis of data that is too massive or complicated for typical database systems are all handled by big data architecture.
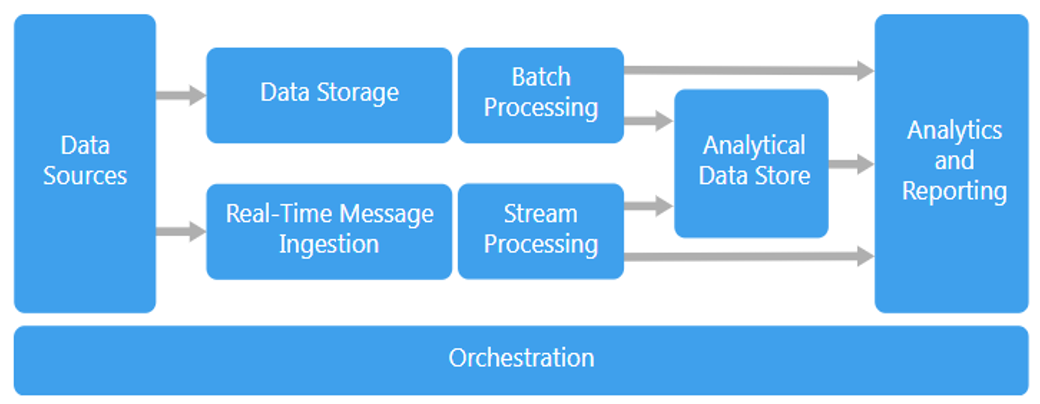
Fig: Big Data Architecture is made up of several components.
Big Data Architecture Processes
- Data Sources and their connectivity: Connectors and adapters are capable of efficiently connecting any format of data and may be used to connect to a wide range of various storage systems, protocols, and networks.
- Data Governance: In data governance, privacy and security provisions are implemented throughout the data lifecycle, from the point of ingestion to the point of processing, analysis, storage, and deletion.
- Systems Management: Modern big data architectures are often built on top of highly scalable, large-scale distributed clusters, which must be continuously monitored through the use of centralized administration consoles.
- Preserving the Quality of Service: The Quality of Service framework assists in the definition of data quality, compliance regulations, ingestion frequency and size, and other aspects of service delivery.
Components of Big Data Architecture
The majority of big data architectures incorporate some or all of the following features:
1. Managing big data sources
A big data environment can manage both batch and real-time processing of big data sources, including as data warehouses, relational database management systems, cloud-based applications, and Internet of Things devices. All big data solutions begin with one or more data sources, depending on their complexity. Examples include the following:
- Application data stores, such as relational databases.
- Static files are files created by applications, such as web server log files, that do not change over time.
- Data sources updated in real time, such as Internet of Things devices.
2. Data storage
Typically, data for batch processing activities is stored in a distributed file store, which is capable of storing enormous volumes of large files in a variety of formats. It receives data from a source, translates the data into a format that is understandable by the data analytics tool, and saves the data in the format that was converted from the source. A data lake is a term used to describe this type of storage. Azure Data Lake Store and blob containers in Azure Storage are two options for establishing this storage.
3. Batch processing
Batch processing is a method of completing tasks in a set amount of time. All of the data is divided into distinct categories or chunks, which is accomplished through the use of long-running processes that filter and aggregate the data, as well as prepare the data in a processed condition for analysis. This type of job often makes use of sources, processes them, and then transfers the result of the processed files to the new files. Batch processing can be accomplished in a variety of ways. Reading source files, processing them, and publishing the output to new files are typical tasks associated with this type of work. Running U-SQL jobs in Azure Data Lake Analytics, using Hive, Pig, or custom Map/Reduce jobs in an HDInsight Hadoop cluster, or executing Java, Scala, or Python programmes in an HDInsight Spark cluster are all options available.
4. Real-time message ingestion
If the solution involves real-time sources, the architecture must have a reliable means to capture and store real-time messages in order to perform stream processing operations. This may be as basic as a data store, where incoming messages are dumped into a folder and processed from there, for example. Many solutions, however, require a message ingestion store in order to serve as a buffer for messages and to allow scale-out processing, dependable delivery, and various messages queuing semantics, among other things. Azure Event Hubs, Azure IoT Hubs, and Kafka are some of the available options.
5. Stream processing
Filtering, aggregating, and otherwise preparing the data for analysis are all necessary steps after real-time signals have been captured by the solution. The data from the processed stream is written to an output sink after it has been processed. Azure Stream Analytics is a managed stream processing solution that operates on unbounded streams and is based on SQL queries that are permanently running in the background. When running an HDInsight cluster, we can also make use of open source Apache streaming technologies such as Storm and Spark Streaming.
6. Analysis and reporting
With the help of analysis and reporting, big data solutions are able to deliver insights into their data. A data modeling layer, such as a multidimensional OLAP cube or a tabular data model in Azure Analysis Services, may be included in the design to enable users to perform data analysis on the information. It may also offer self-service business intelligence (BI), which would make use of the modeling and visualization features found in Microsoft Power BI or Microsoft Excel. Analysis and reporting can also take the form of interactive data exploration by data scientists or data analysts, as well as traditional reporting.
7. Orchestration
Most big data solutions are comprised of repeated data processing operations, which are encapsulated in workflows. These workflows transform source data, transfer information among various sources and sinks, store processed data in an analytical data store, or output the results to a report or dashboard. Automation of these activities can be accomplished through the use of orchestration technologies such as Azure Data Factory, Apache Oozie, or Apache Hadoop and Sqoop.
Reference: Big data architectures
Advertisement
Advertisement