Home »
Python »
Python programs
Emotional and Sentiment Analysis with the help of Python
Python | Emotional and Sentiment Analysis: In this article, we will see how we will code the stuff to find the emotions and sentiments attached to speech?
Submitted by Abhinav Gangrade, on June 20, 2020
Modules to be used:
nltk, collections, string and matplotlib modules.
nltk Module
The full form of nltk is "Natural Language Tool Kit". It is a module written in Python which works on the human language like what are the sentiments and emotions attached to it.
How can we Download it?
General Way:
pip install nltk
Pycharm Users:
Go to the project interpreter and install it.
Now after downloading this module, it does not mean that we can use its every package, for this we have to download its every package in this way,
-
Create a blank .py file and write this code in it,
# import the nltk module
import nltk
# write this command
nltk.download()
And, run the file
-
Now after running this file, the compiler will show you the interface like this,
NLTK Downloader
---------------------------------------------------------------------------
d) Download l) List u) Update c) Config h) Help q) Quit
---------------------------------------------------------------------------
Downloader>
Write d as we have to download the packages of nltk in it.
After this:
Download which package (l=list; x=cancel)?
Identifier>
Write all in this ass we have to Download all packages of nltk
in our system,and after pressing enter this will take some time
as it is big file.
Note: You must have a good internet connection while
you are downloading this files.
This is all about nltk.
Collections Module:
collections is an inbuilt python module that provides us various functions like the counter in which you just give our list and it will return us a dictionary with the count of the elements.
matplotlib Module:
matplotlib is a python library that will help us to plot graphs and all. In this, we will use this library to plot the emotions and sentiments graph.
How we will find the emotions and sentiments?
First of all, we will create a blank text file in which we will write or paste our speech (for which we have to find the emotions and sentiments) and we will read this file and tries to make each word a lower word(with the help of .lower() function) and now after this, we will remove the punctuations from the text and also remove the newline characters from the text and after this, we will make the text tokenize with the help of nltk module (Tokenize means splitting the text into the list (we can also do it with the help of .split() function but nltk will be faster than this) ), Now after tokenizing we will remove the stopwords (Stopwords means the words which have no emotion) with the help of nltk function and after that we will find the emotions and sentiments attached to the remaining words and will plot it with the help of matplotlib.
We will see the various functions of nltk,
- nltk.tokenize: Tokenize is a package of nltk and this package provides a function words_tokenize which will tokenize our text and create a list.
- nltk.corpus: Corpus is a package of nltk and this package provides us a function stopwords which will remove the stopwords from our tokenize words.
- nltk.sentiment.vader: The sentiment is a package of nltk and vader is a library inside this package which will provide us a Function named, SentimentIntensityAnalyzer which will calculate the sentiments attached to our text with the help of polarity_scores().
The link to the emotions.txt file is: https://github.com/abhinav0606/SentimentAnalysisNLTK/blob/master/emotion.txt
Or, download here: emotion.txt
I have a taken the speech of Mark Zuckerberg which he gave at Harvard.
Let's see the code,
# import the libraries
# import nltk.tokenize
from nltk.tokenize import word_tokenize
# import nltk.corpus
from nltk.corpus import stopwords
# import nltk.sentiments.vader
from nltk.sentiment.vader import SentimentIntensityAnalyzer
# import string to remove punctuations
import string
import matplotlib.pyplot as plt
from collections import Counter
# Create a blank text file mine is
# speech.txt where we will write the speech
# open and read the file
text=open("speech.txt").read()
# we learned in the previous article
# we have to make the text lower
# and remove the punctuations
# make it lower
text=text.lower()
# remove the new line character
text=text.replace("\n","")
# remove the punctuations
# Now we will use the
# str.maktrans(<to replace>,<with whom to replace>, <to remove>)
# as we want to remove the punctuations
text=text.translate(str.maketrans("","",string.punctuation))
# Now our text is clean
# now make it tokenize
tokenize_words=word_tokenize(text)
# now remove the stopwords
# make a empty list where we
# will keep our clean words
clean_words=[]
for i in tokenize_words:
# now nltk provides a stopwords list
# if our i present in it we will not
# store it
if i not in stopwords.words("english"):
clean_words.append(i)
# now we have the clean list without stopwords
# now we have the emotions file as emotion.txt
# now we will find the emotions attached to the
# clean words
# create a emotions empty list
emotions=[]
with open("emotion.txt","r") as file:
for i in file:
# now we have to modify the emotions
text1=i.replace("\n","")
text1=text1.strip()
text1=text1.replace(" ","")
text1=text1.replace(",","")
text1=text1.replace("'","")
# now our emotions file get modified
# now the file is like
# words:emotion
# now we will split the text
word,emotion=text1.split(":")
# now we will check the words
# in clean words
if word in clean_words:
emotions.append(emotion)
# now we have catched the emotions
# now we will catch the sentiment
# will create a function
def sentimentanalysis(text):
return SentimentIntensityAnalyzer().polarity_scores(text)
# now we will find the sentiment attached to it as this
# function returns a dictionary
sentiments=sentimentanalysis(text)
# now we will find the counter of emotions
emotions_counter=Counter(emotions)
# now we will print the emotions and sentiments
print(emotions_counter)
print(sentiments)
# now we will plot the graph
# we will create a figure
# this is for emotions
fig1,ax1=plt.subplots()
ax1.bar(emotions_counter.keys(),emotions_counter.values())
# to make the words inclined
fig1.autofmt_xdate()
# this is for sentiments
fig2,ax2=plt.subplots()
ax2.bar(sentiments.keys(),sentiments.values())
fig2.autofmt_xdate()
# will show the plot
plt.show()
Output:
Counter({'happy': 5, 'hated': 2, 'entitled': 2, 'attached': 1,
'attracted': 1, 'alone': 1, 'free': 1, 'loved': 1})
{'neg': 0.085, 'neu': 0.756, 'pos': 0.159, 'compound': 0.9996}
The plots are,
1) Emotions Graph:
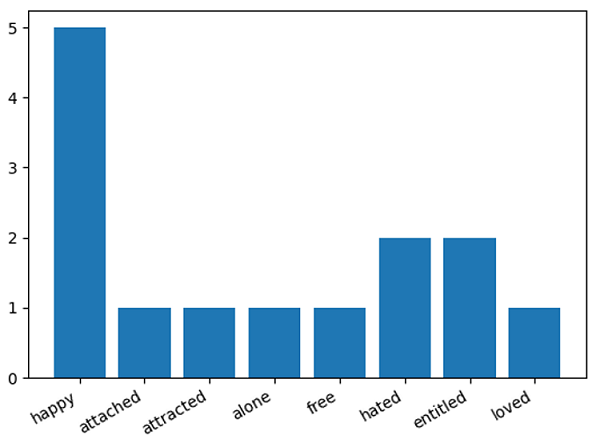
2) Sentiments Graph:
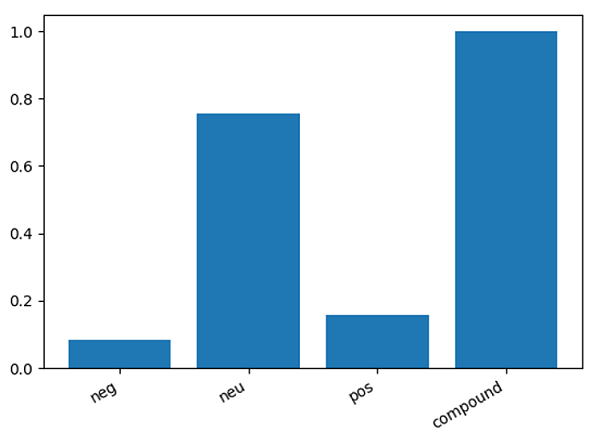
Advertisement
Advertisement