Home »
Cloud Computing
MapReduce in Cloud Computing
MapReduce: In this tutorial, we will learn about MapReduce and the steps of MapReduce in Cloud Computing.
By Rahul Gupta Last updated : June 04, 2023
MapReduce
MapReduce is an approach to computing large quantities of data. This allows the workload to be distributed over a large number of devices. A structured way to apply this programming model is using the map and reduce.
It takes a set of pairs of key/value inputs and generates a set of pairs of key/value outputs. Two fundamental operations are included in the computation: map and reduce.
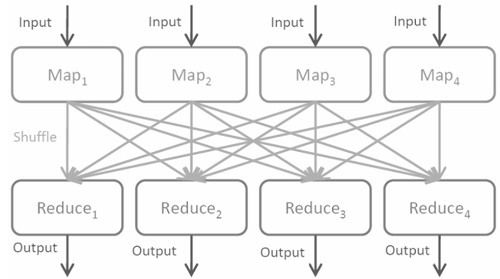
Fig: Map and Reduce
The user-written Map operation takes an input pair and generates a set of intermediate key/value pairs. The Map-Reduce library gathers all the intermediate values associated with the same intermediate Key #1 together and transfers them to the Reduce function.
MapReduce Operations
A framework (or system) for MapReduce is usually composed of three operations (or steps):
- Map: The map function is applied to the data by each worker node and writes the output to temporary storage. A master node ensures that it processes only one copy of the redundant input data.
- Shuffle: Worker nodes redistribute data based on output keys (produced by the map function) so that the same worker node is located on all data belonging to a single key.
- Reduce: Worker nodes are now processing every group of output data in parallel, per key.
MapReduce enables distributed map processing and reduction operations to be carried out. Maps may be carried out in parallel if each mapping operation is independent of the others; this is restricted in practice by the number of independent data sources and/or by the number of CPUs near each source. Similarly, the reduction step may be performed by a group of 'reducers' given that all outputs of the map operation that share the same key are simultaneously presented to the same reducer, or that the reduction function is associative. Although this approach also appears to be inefficient compared to more sequential algorithms (because many instances of the reduction process have to be run), MapReduce can be applied to considerably larger datasets than a single "commodity" server can handle-a large server farm can use MapReduce in only a few hours to sort a petabyte of data. The parallelism also provides some possibility of recovery during the process from partial server or storage failure: if one mapper or reducer fails, the job can be rescheduled, assuming that the input data is still available.
MapReduce Steps
Followings are the key steps of MapReduce -
- Prepare the Map() input: The Map-Reduce scheme designates map processors, assigns the K1 input key that each processor will run on, and provides all the input data associated with that key to that processor.
- Run the user-provided Map() code: Map () is executed for each K1 key exactly once, producing output ordered by the K2 key.
- "Shuffle" the Map output to the Reduce processors: The Map-Reduce framework designates processors for reduction, assigns the K2 key that each processor should operate on, and provides all the map-generated data associated with that key to that processor.
- Run the user-provided Reduce() code: For each K2 key generated by the Map stage, Reduce () is run exactly once.
- Produce the final output: All the Reduce output is obtained by the Map-Reduce method and sorted by K2 to generate the final result.
Advertisement
Advertisement