Home »
Python »
Python Programs
How do I remove rows with duplicate values of columns in pandas dataframe?
Given a pandas dataframe, we have to remove rows with duplicate values of columns in pandas dataframe.
By Pranit Sharma Last updated : October 03, 2023
Pandas is a special tool that allows us to perform complex manipulations of data effectively and efficiently. Inside pandas, we mostly deal with a dataset in the form of DataFrame. DataFrames are 2-dimensional data structures in pandas. DataFrames consist of rows, columns, and data.
Problem statement
Suppose we are given a pandas DataFrame with some columns like c1, c2, and c3. c1 and c2 contain some string and integer values respectively and we need to identify them in one column, if two values are the same, we need to drop the duplicate values from that particular value.
Removing rows with duplicate values of columns in pandas dataframe
We can perform this operation on more than one column by creating a subset of columns and passing it inside pandas.DataFrame.drop_duplicates() method (Return DataFrame with duplicate rows removed).
Let us understand with the help of an example,
Python program to remove rows with duplicate values of columns in pandas dataframe
# Importing pandas package
import pandas as pd
# Import numpy
import numpy as np
# Creating a dictionary
d = {
'c1':['cat','bat','cat','dog'],
'c2':[1,2,1,1],
'c3':[0,1,2,3]
}
# Creating DataFrame
df = pd.DataFrame(d)
# Display original DataFrame
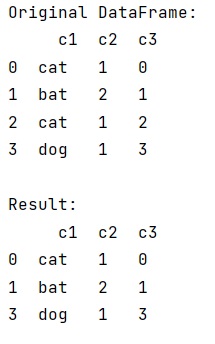
print('Original DataFrame:\n',df,'\n')
# Dropping duplicates
res = df.drop_duplicates(subset=['c1','c2'], keep='first')
# Display result
print("Result:\n",res,"\n")
Output
The output of the above program is:
Python Pandas Programs »
Advertisement
Advertisement